如何使用FFmpeg的解码器—FFmpeg API教程
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
本文的代码下载地址:GitHub,编译环境是 Qt 5.15.2 跟 MSVC2019_64bit 。
跟解码相关的结构体如下:
1,AVCodecContext,这个结构体可以是 编码器 的上下文,也可以是 解码器 的上下文,两者使用的是同一种数据结构。
2,AVCodec,编解码信息。
3,AVCodecParameters,编解码参数。
4,AVPacket ,数据包(已编码压缩),这里面的数据通常是一帧视频的数据,或者一帧音频的数据。AVPacket 他本身是没有编码数据的,他只是管理编码数据。
5,AVFrame ,解码之后的 YUV 数据。AVFrame 跟 AVPacket 类似,都是一个管理数据的结构体,他们本身是没有数据的,只是引用了数据。
跟解码相关的API函数如下:
1,avcodec_alloc_context3,通过传递 AVCodec 编解码信息来初始化上下文。
2,avcodec_parameters_to_context,把流的 AVCodecParameters 里面的 编解码参数 复制到 AVCodecContext 。
3,avcodec_open2,打开一个编码器 或者 解码器。
4,avcodec_is_open,判断 一个编码器 或者 解码器 是否打开
4,avcodec_send_packet,往 AVCodecContext 解码器 发送一个 AVPacket 。
5,avcodec_receive_frame,从 AVCodecContext 解码器 读取一个 AVFrame。
我需要着重讲一下 AVCodec 跟 AVCodecParameters 这两个结构体。
1,AVCodec 里面放的是 编解码信息 。
2,AVCodecParameters 里面放的是 编解码参数。
怎么理解 编解码信息 跟 编解码参数?
通常 AVCodec 是使用 avcodec_find_decoder 函数找出来的,你给这个函数一个 AVCodecID,他就能返回一个解码器指针给你。这是 引入 FFmpeg 库的时候,他初始化了一堆静态的编解码变量给你。
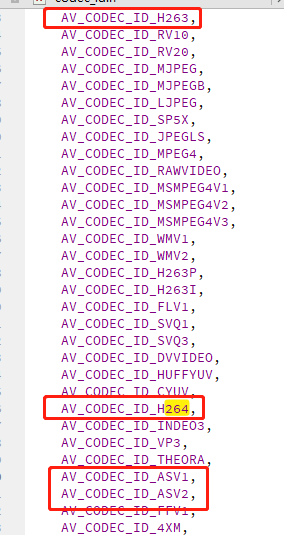
例如 AVCodecID 是 AV_CODEC_ID_H263 ,就会返回 263 相关的 AVCodec 指针, AVCodecID 是 AV_CODEC_ID_H264 ,就会返回 264 相关的 AVCodec 指针。
只要是用 H264 编码 的视频,使用的解码器信息都是一样的,用的是同一个 AVCodec,但是不同的视频文件,宽高,采样这些信息,肯定会有点不一样。
这些不一样的东西放在哪里呢?就是 AVCodecParameters。
当 avformat_open_input 函数打开一个 MP4 的时候,编码器参数就会放在 codecpar 字段里,如下:
fmt_ctx->streams[0]->codecpar
上面的 codecpar 就是一个 AVCodecParameters,只需要用 avcodec_parameters_to_context 函数把 codecpar 的参数复制给 AVCodecContext 即可,很方便。
请先下载本文代码仔细阅读一遍。
下面就来讲解 如何初始化 AVCodecContext ,如何打开解码器,如何往解码器发数据,如何从解码器读取数据,请看下图:

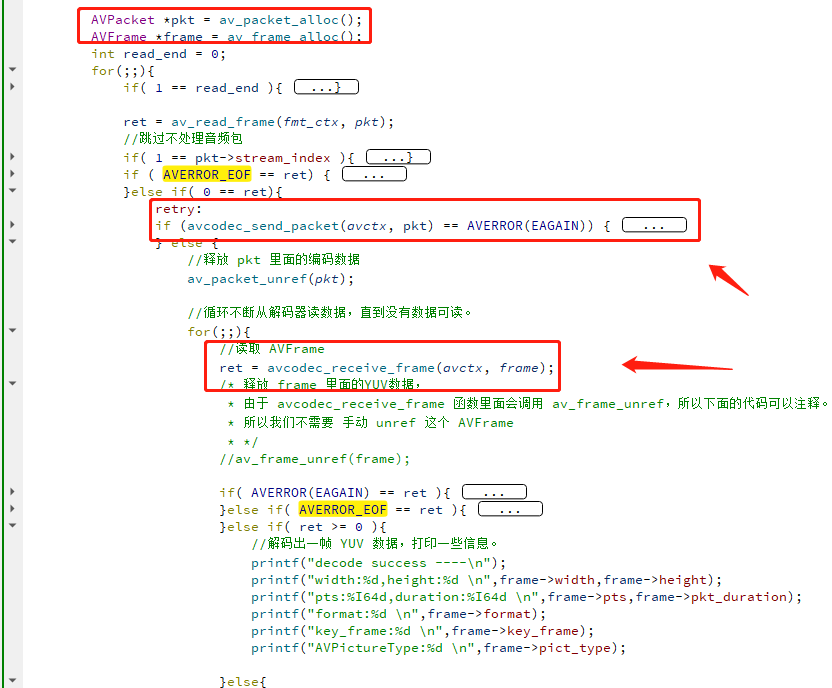
这节的代码有非常多的重点。
1,用到了一个新的结构体 AVFrame , AVFrame 跟 AVPacket 类似,都是一个管理数据的结构体,他们本身是没有数据的,只是引用了数据。
2,打开一个解码器的流程是如下:
avcodec_alloc_context3 ➔ avcodec_parameters_to_context ➔ avcodec_find_decoder ➔ avcodec_open2
avcodec_find_decoder 这个函数是根据 解码器ID 来找到一个 AVCodec ,FFmpeg 在 codec_id.h 定义了很多解码器ID,如下:
avcodec_alloc_context3 跟 avcodec_open2 这两个函数都可以接受 AVCodec 参数,选一个函数来接受即可,千万不要往这两个函数传递不一样的 AVCodec 参数。
avcodec_parameters_to_context 这个函数主要用来做什么的呢?不调这个函数,直接打开解码器会有问题吗?这个后续解答。
3,视频解码流程是这样,往一个解码器发一个 AVPacket ,不一定立马就能拿到 一个 AVFrame,因为视频可能有 B 帧,不了解 B 帧的请自行 Google。
所以上面的代码逻辑是,发一个 AVPacket,就 死循环不断的读解码器,直到 返回 EAGAIN,循环是因为有可能有多个 AVFrame 需要读取。
如果返回 EAGAIN ,那就代表解码器需要输入更多的 AVPacket ,才能解码出 AVFrame。
如果已经读到 文件末尾,没有 AVPacket 能从容器里面读出来了,怎么办?
这时候就需要 往 解码器发一个 size 跟 data 都是 0 的 AVPacket ,这样解码器就会把它内部剩余的帧,全部都刷出来。
当解码器完全没有帧可以输出的时候,就会返回 AVERROR_EOF。
所以,avcodec_receive_frame() 主要有两个返回值,如下:
1,EAGAIN,代表解码器需要输入更多的 AVPacket ,才能解码出 AVFrame。
2,AVERROR_EOF,代表解码器结束了,只有你给他发了 NULL 的 AVPacket 才会返回 AVERROR_EOF,通常只有在读取完文件内容,才会发送 NULL 的 AVPacket 给解码器。
音频解码器也是一样的流程。
上面的代码,运行之后会打印出以下信息。

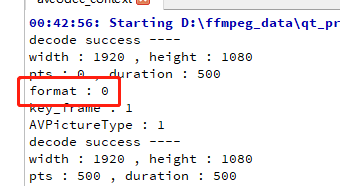
上面打印的都是 AVFrame 这个结构体的字段,
1,width 跟 height 是图片的宽高,很明显 这是一个 1920 x 1080 的图片。
2,pts,此帧视频的显示时间,第一帧通常是 0 ,也有一些文件把第一帧视频的pts改大,例如改成1000,但第一帧音频的pts还是保留为 0,这种视频开始只有声音,界面是黑屏的。
不过这种情况也看 播放器怎么处理,我用迅雷看的时候,迅雷播放器不管。还是一开始就显示视频。
所以这就是 音视频的复杂之处,各种格式的字段特别多,而且有些没有标准,就说这个 pts,是不是第一帧一定要是 0,也没规定。不同的播放器处理还不一样。
3,format,打印出来是 0 ,这个其实是 AVPixelFormat 枚举的类型,0 代表 AV_PIX_FMT_YUV420P ,如下:
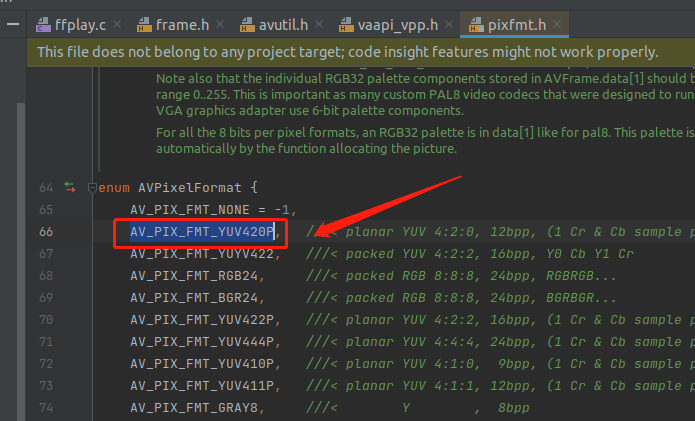
上图这种写法比较省笔墨,第一个是 -1 ,后面的就会自己递增。
4,key_frame ,这个字段代表当前帧是不是关键帧,正确的术语其实是 IDR 帧,全称 Instantaneous Decode Refresh(独立的立即刷新帧),第一帧通常都是关键帧,,
5,pict_type,这个是 AVPictureType 枚举的类型,1 代表 AV_PICTURE_TYPE_I,I 帧。
IDR 一定是 I 帧,但是 I 帧不一定是 IDR 帧。 IDR 帧后面的帧不会再参考 IDR 前面的帧,而 I 帧后面的帧可以参考 I 帧前面的帧。所以对于 H.264 解码器,只要他收到 IDR 帧,就可以把已解码的数据全吐出来释放调内存。因为 IDR 前面的帧不可能再被参考引用了。
前面抛出了一个问题,avcodec_parameters_to_context 这个函数主要用来做什么的呢?不调这个函数,直接打开解码器会有问题吗?
我们来看一下这个函数的实现,如下:
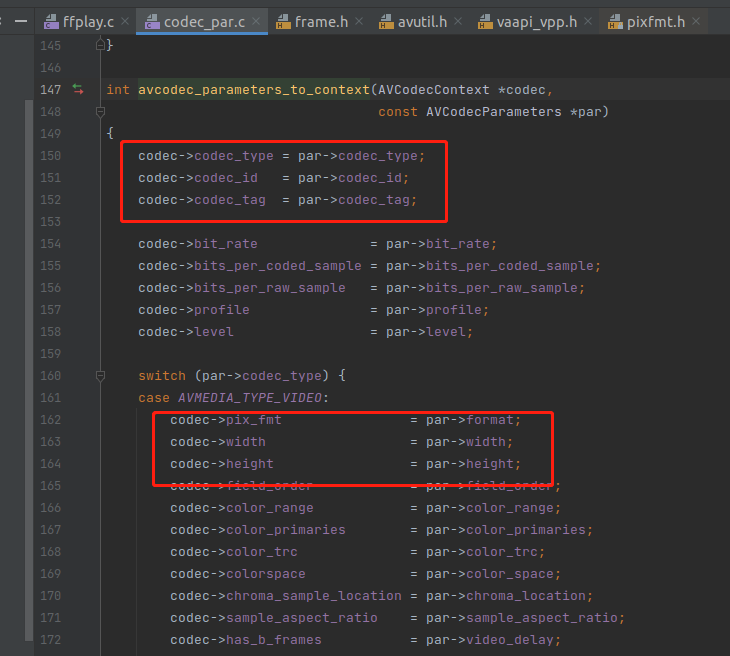
从上图可以看出,就是把一些 宽高,像素格式 复制给 AVCodecContext,因此这个 avcodec_parameters_to_context 函数必须调。
前面的 avcodec_find_decoder 只是根据 codec_id 找到解码器,例如找到 H264 这个解码器了。但是要解码数据,还是需要知道码率,宽高之类的信息。
我实验了一下,如果不调 avcodec_parameters_to_context,会报以下错误。

从前面打印出来的 format 等于 0,0 是 AV_PIX_FMT_YUV420P 宏的值 ,所以解码出来的数据是 yuv420p 的格式,背景知识请看《YUV数据分析》。
AV_PIX_FMT_YUV420P 后面的 p 代表 AVFrame 里面的像数据的内存布局是 planar 格式。
如果没有 p 就是 packed 格式,例如 AV_PIX_FMT_YUYV422 没有 p 后缀,所以它是 packed 格式,这是 FFmpeg 的命名习惯。
实际上像素是如何存储的是通过 AVPixFmtDescriptor 来确定的,推荐阅读《AVPixFmtDescriptor结构》
这里简单讲解一下 planar 跟 packed 的区别,AVFrame 里面有一个 data 字段,它指向的就是 YUV 的数据,他是一个指针数组,如下:

如果是 planar 格式,data[0] 会指向 Y 数据,data[1] 指向 U 数据,data[2] 指向 V 数据。那这些数据的大小是多少呢?还有一个 linesize 数组来管理大小。
我们来验证一下是不是这样样子。yuv420 的格式,U 或者 V 的大小应该是 Y的 4 分之一,如下:
printf(" Y size : %d \n",frame->linesize[0]);
printf(" U size : %d \n",frame->linesize[1]);
printf(" V size : %d \n",frame->linesize[2]);
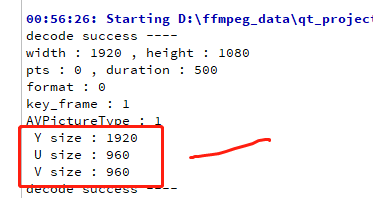
上图是 2分之一,明显不对,为什么会这样呢?因为 linesize 里面是 stride 值。
stride 值 = 图像宽度 * 分量数 * 单位样本宽度 / 水平子采样因子 / 8
分量数就是通道数,因为是 planer ,所以分量数都是1,如果是 packed ,分量数是 3。单位样本宽度 是指 一个 U 占多少位,目前我们是 8 位,就是一个字节。
最重要的是水平采样因子,水平子采样因子指在水平方向上每多少个像素采样出一个色度样本。yuv420 水平方向其实是每两个像素采样一个色度样本,所以是水平采样因子是2。
有些朋友可能不太理解,如果是 2,UV 应该是 Y 的2分之一,不是 4分之一。那是因为还有一个垂直采样因子,yuv420的 垂直采样因子 也是 2 。但是 垂直采样因子 不会影响 stride 值。你就这样理解,UV 的水平采样因子是2,相对于 Y 他们的 height 也少了一半。水平跟垂直都少了一半,就是 4分之一。
所以 frame->linesize 并不是 UV 分量的真实数据大小,而是一个 stride 值。这个值可能还会内存对齐。
关注 stride 的知识,请看《图像步幅》
如果是 packed 格式 ,YUV 是交替存储,例如 YUVYUVYUV,这样子,这时候 data[0] 就指向所有的数据,而 linesize[0] 代表这帧图片的大小。
在 packed 格式 里 data[1] 跟 data[2] 都是没有用。
这里讲个扩展知识,即使是 planar 的视频格式,也只用到 3 个下标,为什么 AV_NUM_DATA_POINTERS 是 8 ,为什么要定义一个 8 大小的数组。不是浪费了其他 5 个指针吗?
这是因为 音频帧 跟 视频帧 共用 AVFrame 的结构,音频帧有些是 8 声道交响曲,有前有后,有左有右。
那是不是音频帧只能支持 8 声道?9声道 ffmpeg 就不支持了?也不是,他还有一个 extended_data 来指向高于 8 声道的数据。
这里不要误会,extended_data 并不指向第9声道数据,extended_data 跟 data 是一样的,只是你可以用 extended_data[8] 获取到第9声道的数据。
对于视频帧,最多就用了 3个下标,所以用 data 还是 extended_data 来获取数据都是一样的,但是 ffmpeg.c 使用的是 extended_data
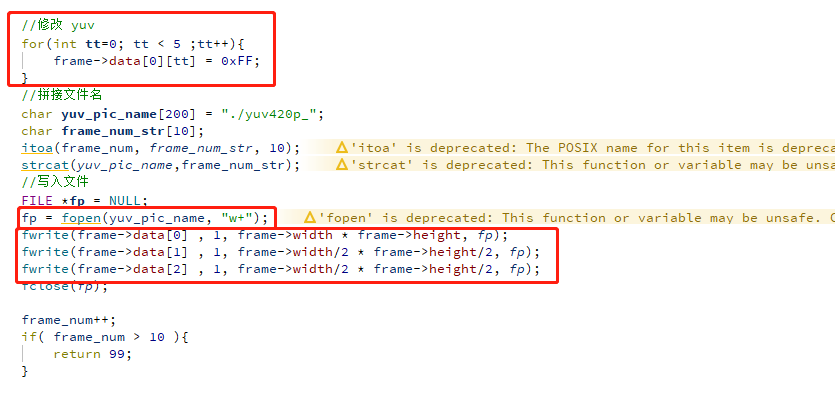
下面就来加一些小功能,来融会贯通一下前面的知识。修改一下解码之后的 yuv 数据,然后保存成 yuv 图片文件。
从前面得知,data[0] 就是 Y 数据,那我们把前面 5 个像素的 Y 改成 FF,他就会变成白色。在 《YUV数据分析》一本中做过类似的实验,当时是手动修改。
由于 YUV 图片是裸数据,没有什么头部之类的格式,我们直接把 data 存储到文件即可。代码如下:
运行之后,用 7yuv 打开查看,可以看到顶部的 5 个像素被改了,如下:
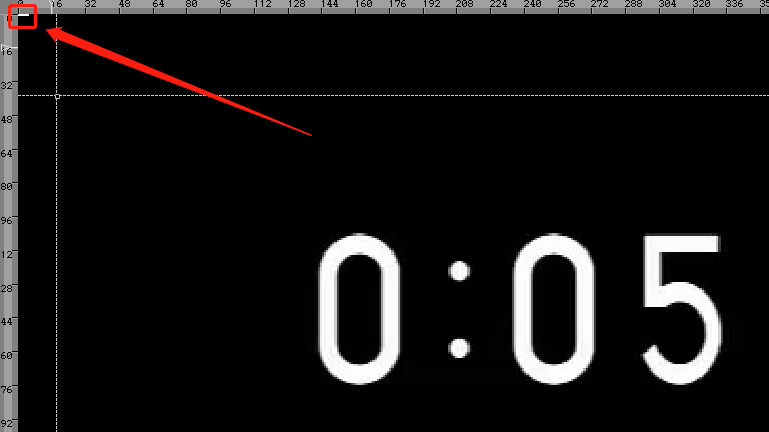
这里讲一个扩展知识,上面的代码 fopen 打开文件的使用 使用了 wb,必须用二进制方式打开文件。要不会导致一些诡异的问题,例如图片拉伸,如下:
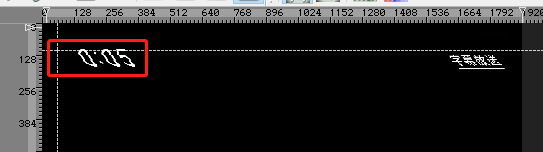
从上图可以看到,字体倾斜了,具体原因请看《fopen等:文本方式和二进制方式打开文件的区别》
FFmpeg 也有类似的命令,可以把视频转成图片,下面是提取第一帧转成图片,命令如下:
ffmpeg -i juren-30s.mp4 -vframes 1 -pix_fmt yuv420p -f rawvideo yuv420p-888.yuv
上面的命令是使用 yuv 复用器实现的。
ffmpeg 本身封装了一个 yuv 的复用器,不用自己打开文件写入文件。这样会容易出问题,例如不小心把 wb 写成 w。
从函数使用角度来看 yuv 其实也是一种封装格式,跟 mp4 同一个级别的。yuv 的封装格式叫 rawvideo,代码文件是 libavforamt/rawenc.c
如下:

从上图可以看出,yuv 的复用器 rawenc.c 是跟 mp4 的· mov.c 同一个目录的。所以我把 yuv 复用器看成是一个伪复用器。
虽然 yuv 跟 mp4 在标准定义上是完全不同的东西,但是 FFmpeg 这么封装,使用上确实比较好用,可以让逻辑更加通用跟清晰。
FFmpeg 还有一些其他功能也是定义一个 伪工具 来实现的。
参考文章:
1,《色彩空间与像素格式》 - 叶余
