do_audio_out音频编码封装—ffmpeg.c源码分析
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
相对于 《do_video_out视频编码封装》,《do_audio_out音频编码封装》 就显得非常简单,但是有些逻辑也是类似,例如 ost->sync_opts 的用法。
ost->sync_opts 依然是一个预估的时间,当 AVFrame 的 pts 没有值的时候,就会用 ost->sync_opts 来代替,如下:
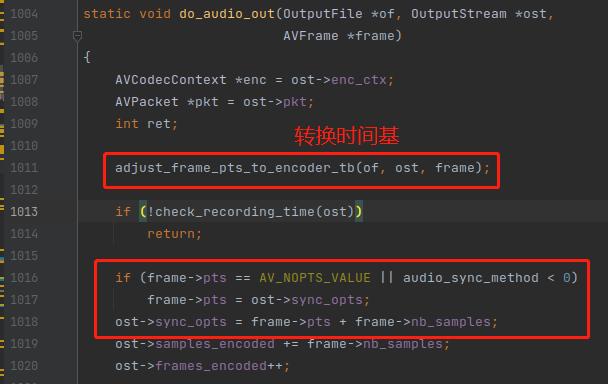
ost->sync_opts 是通过 AVFrame 的样本数来计算出来的。
由于 AVFrame 是从滤镜里面出来的,所以它的 pts 的单位是滤镜的时间基,滤镜的时间基可以通过 av_buffersink_get_time_base() 函数获得。
adjust_frame_pts_to_encoder_tb() 函数就是用来把 AVFrame 的 pts 的单位从 滤镜的时间基 转换成 编码器的时间基 的,
adjust_frame_pts_to_encoder_tb() 不仅仅是转换时间基,它的返回值也是比较精妙的,如下:
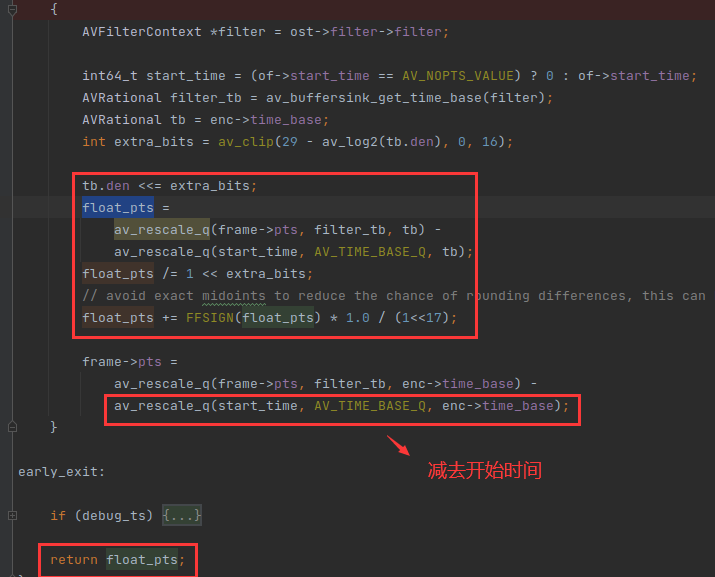
float_pts 的单位是秒,但是他的精度很高,用了 extra_bits 来位移,确保从 滤镜时间基 转成 编码器时间基 的时候,没有丢失精度。
上面的函数还有一个重点,就是frame->pts 会减去 start_time,这是为什么呢?
start_time 其实是 命令行 -ss 的值,-ss 可以指定从哪里开始裁剪输出流,裁剪是通过 trim 滤镜实现的,虽然裁剪了,但是滤镜处理的 AVFrame 的 pts 没有进行裁剪的。
例如你命令行用 -ss 60 从第 60 秒开始裁剪输出流,也就是从 buffersink 滤镜容器出来的第一个 AVFrame 的 pts 就是 60,所以需要减去 start_time ,把它变成第一帧。
如果没使用 -ss 选项,那 start_time 的值就是 0 。
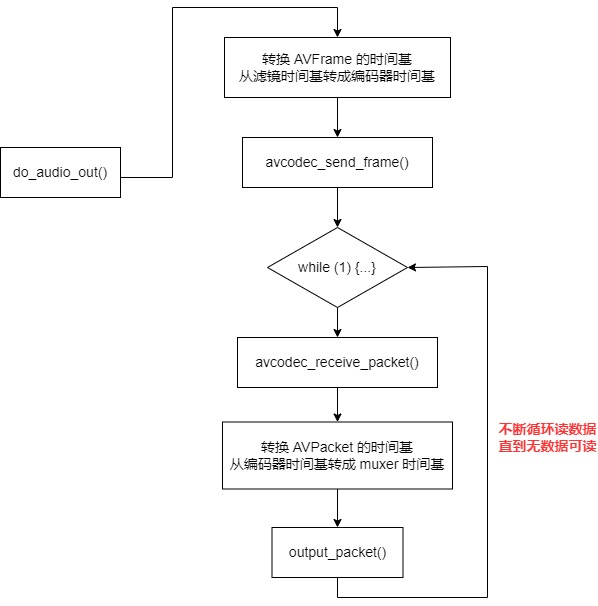
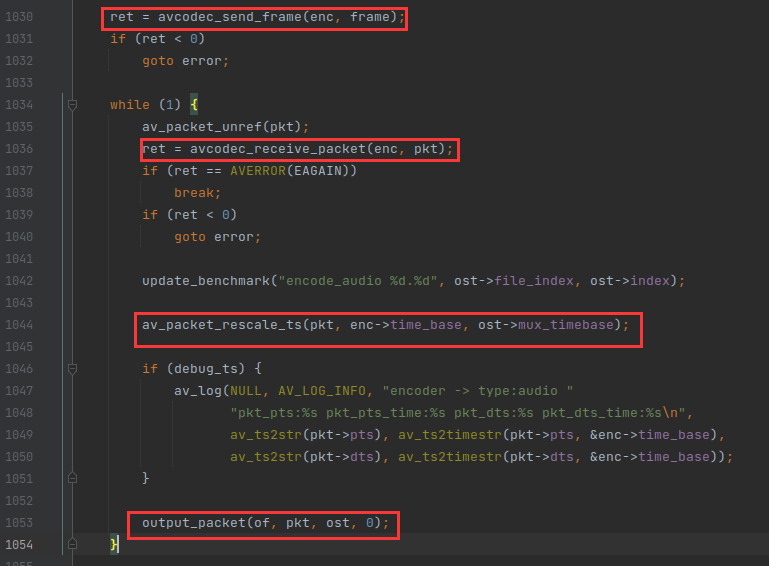
do_audio_out() 函数后面的流程就非常简单了,就是调 avcodec_send_frame() 往编码器发数据,用 avcodec_receive_packet() 从编码器读数据,最后转换 AVPacket 的时间基,从编码器的时间基转成 muxer 的时间基。
最后调 output_packet() 写入文件就可以了。output_packet() 是一个公共函数,写入音频的 AVPacket 是它,写入 视频的 AVPacket 也是它。
do_audio_out() 函数的整体流程图如下: