FFmpeg内存对齐—FFmpeg API教程
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
内存对齐是计算机编程提高性能的一种方式,我们平时用的 struct,malloc() 都会进行内存对齐,如下代码:
struct {
int x;
char y;
}s;
int main(){
printf("%d\n", sizeof(s)); // 输出8
return 0;
}
32位系统中,上面的代码中 int 占 4 字节,char 占 1 字节,但是结果会输出 8 ,这是因为编译器自动帮我们做了内存对齐。
而 malloc() 函数也会进行内存对齐,32位系统里面,malloc 函数返回的地址是以8字节对齐,在64位系统是以16字节对齐的。
为什么要做内存对齐呢?为了提高内存的访问效率,举个例子。
因为某些32位的 CPU,每个总线周期都是从偶地址开始读取32位的内存数据的,假设一个 int 变量的地址是 0x01,当 执行汇编指令 mov %eax,0x01 的时候,CPU 内部需要做比较多的额外的功能,首先CPU 从 0x00 开始读取 4 字节数据,然后把第一个字节丢弃,然后从 0x04 开始再读取 4 字节,把后面 3个字节丢弃,然后把第一次 读到的 3 字节数据 跟第二次读到的 1 个字节数据合并在一起,然后再 mov 到 eax 寄存器。
不过这个过程是 CPU 内部做的,你在汇编代码是看不见这个过程的。不过由于内存不对齐,CPU 干了这么多额外的事情,肯定会有性能损耗,这是可以测试出来的。
扩展知识:目前 x86 和 arm 默认都允许不对齐了,arm 可以启用不对齐抛异常。
下面演示一个 xxx 的例子,如果不对齐内存,性能有多少损耗。
TODO:后面补充一个例子。读者有例子提供,欢迎留言。
虽然编译器会自动做内存对齐,malloc 也会做内存对齐,但是由于 FFmpeg 里面用了一些汇编优化,所以 FFmpeg 对内存对齐做了一些扩展,就是 av_malloc 函数。
因为 malloc 函数只能是 16 字节对齐,而如果用到 AVX 指令,需要对齐到更大的字节,AVX512 支持 64 字节的内存操作。下面看一下 av_malloc 的内部实现,如下:
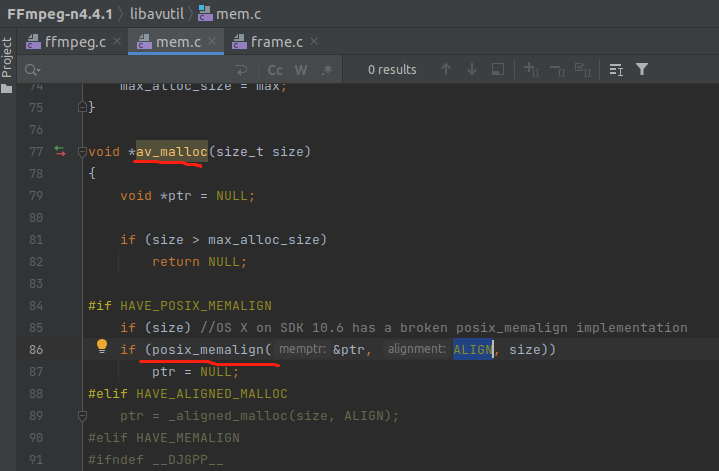
可以看到,用的是 posix_memalign 函数来自定义对齐大小,ALIGN 宏的定义如下:
#define ALIGN (HAVE_AVX512 ? 64 : (HAVE_AVX ? 32 : 16))
可以看到,就是根据 是否有 AVX 指令来判断对齐的。
除了 av_malloc 有内存对齐之外,还有很多的函数,都有一个对齐大小参数,例如最常用的函数 av_image_get_buffer_size ,定义如下:
/**
* Return the size in bytes of the amount of data required to store an
* image with the given parameters.
*
* @param pix_fmt the pixel format of the image
* @param width the width of the image in pixels
* @param height the height of the image in pixels
* @param align the assumed linesize alignment
* @return the buffer size in bytes, a negative error code in case of failure
*/
int av_image_get_buffer_size(enum AVPixelFormat pix_fmt, int width, int height, int align);
主要的是最后一个参数 align ,对齐参数,剧透一下,align 实际上只对 width 进行对齐,不会对 height 对齐。也就是只会对水平采样进行对齐,不会对垂直采样进行对齐。
下图的代码是 av_image_get_buffer_size 函数的使用例子。
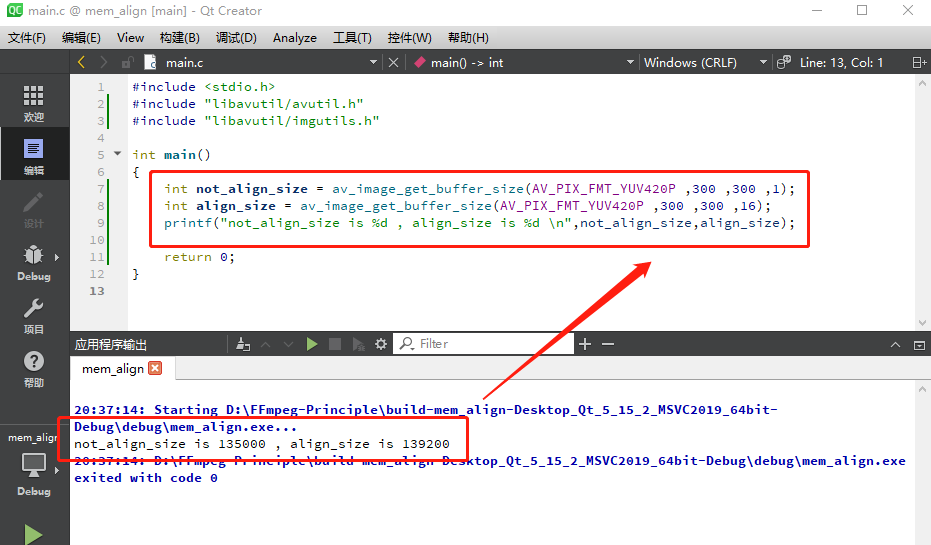
可以看到,这是一个 YUV420p 格式的 300 x 300 的一个图片,未对齐占用 135000 字节 。由于是 YUV420 的格式,所以一个像素占 1.5 字节。 如果按 16 字节对齐,就会占用 139200 字节。这个 1392000 是如何计算出来的呢?
答:对于 yuv420p 格式,Y 分量是100% 采样的,所以水平采样 Y 有 300 个。但是在水平方向 U 或者 V 的采样是 50%,所以 U 或者 V 在水平方向上是 150 个采样。
注意,我这里说的是 水平方向。在垂直方向上,UV 的采样也是 50%,但是我们暂时不需要关注垂直采样。
300 对齐 16 之后,就是 304,也就是如果我想获取水平方向上的一行 Y 分量,直接从 AVFrame 的 data[0] 地址读取 304 字节即可。如果要读取第二行的 Y 数据,就是 data[0] + 304 的地址。
他们的内存结构如下图:
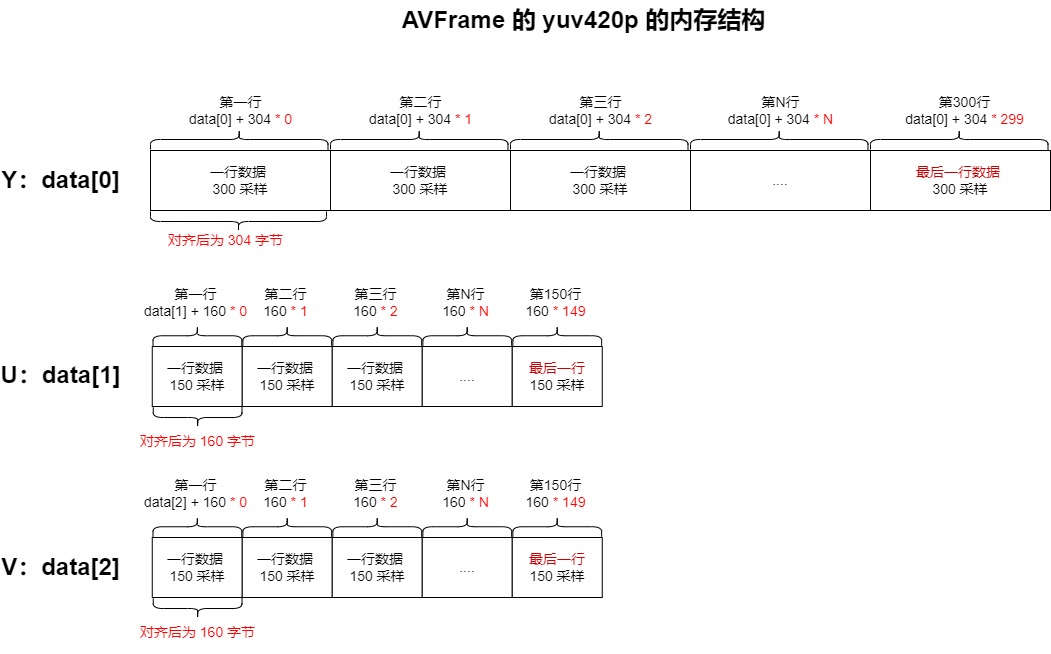
注意上图, 虽然 YUV 的 采样都分为 水平 以及 垂直 两种,也就是二维的采样,但是在 AVFrame 里面其实是把 二维数组映射成 一维数组了。300 行的 Y 采样,全部都放在 data[0] 里面。
注意:U/V 在水平采样上已经 比 Y 少了 50%,Y 每行是 300 采样,U/V 每行是 150 采样。然后 U/V 的垂直采样也比 Y 分量少 50%,具体表现是 Y 有 300 行, U/V 只有150 行。
所以,在未对齐的时候,U 的数据量是 Y 的 四分之一,V 的数据量也是 Y 的四分之一。
垂直采样这个词可能不太好懂,你可以简单把他看成是隔行采样,例如只取第1行,第3行,第5行的数据存储。
因此对齐后的大小 1392000 的计算过程如下:
下面来分析一下 av_image_get_buffer_size 函数的内部流程图,如下:
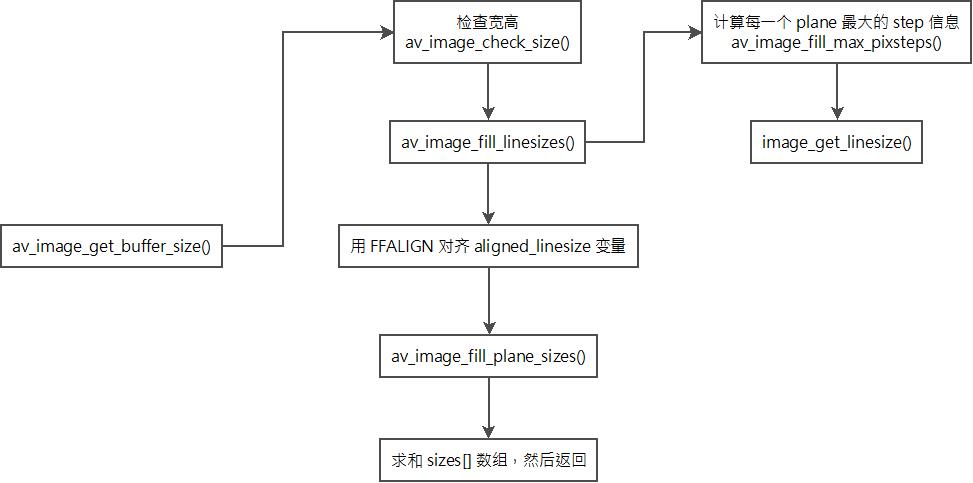
下面来分析一下 av_image_get_buffer_size 函数的代码实现,如下:
提醒:读者可以用 clion 直接断点进去 av_image_get_buffer_size 函数跟踪流程。推荐阅读《用Ubuntu18与clion调试FFmpeg》
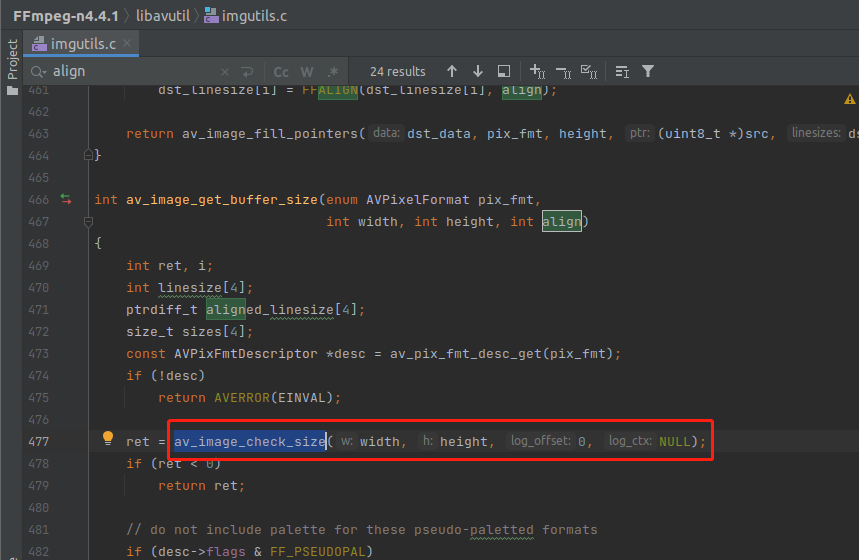
可以看到,他内部会先检查一下 width 跟 height 是否正确,他是怎么检查的呢?再来看一下 av_image_check_size 的内部实现。

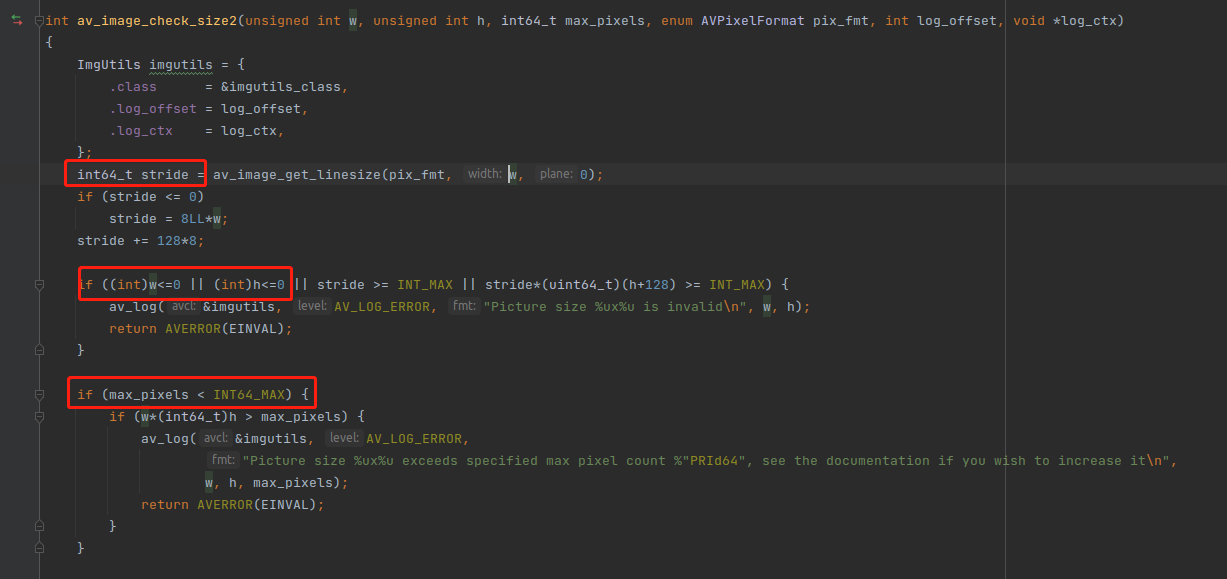
可以看到,实际上就是检查 width 跟 height 不能小于0 ,然后还有一些最大像素检查,那个 stride 代表 步幅,实际上就是 width + 填充字节,请阅读《图像步幅》
回到 av_image_get_buffer_size 的代码,注意下面这两句代码。
// do not include palette for these pseudo-paletted formats
if (desc->flags & FF_PSEUDOPAL)
return FFALIGN(width, align) * height;
pseudo-paletted 这种伪格式,会立即对齐返回,只是对 宽度 width 进行了对齐,FFALIGN 函数的实现如下:
#define FFALIGN(x, a) (((x)+(a)-1)&~((a)-1))

可以看到,FFALIGN 就是一个对齐的函数。
接下来到 av_image_fill_linesizes 函数的调用,如下,注意:这个函数只传了 宽度,没有管高度

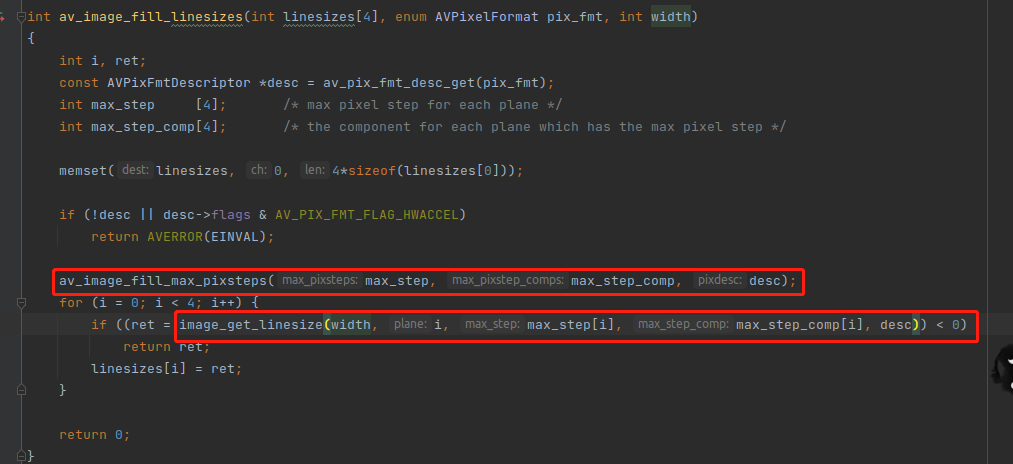
上图中有两个重点:
1,linesizes[] 数组变量,这里面存储的其实是 stride 值,并不是分量的总样本数,因为他没管高度。linesizes[] 数组存的实际上是 width 对齐之后的值,例如 300 按 16 对齐之后是 304,150按16对齐之后是 160。
2, av_image_fill_max_pixsteps() 跟 image_get_linesize() 这两个函数。
av_image_fill_max_pixsteps 函数的作用就是计算出 每一个 plane 的 最大 step 信息,step 是 AVPixFmtDescriptor 结构里面的字段。
FFmpeg 里面有两个术语,component 跟 plane。component 代表 分量,Y就是一个分量 ,U 也是一个分量,V 也是一个分量。而 plane 代表平面,行的意思,plane 代表的是存储方式,虽然 YUV 有 3 个 分量,但不是一定会有 3 个 plane,因为有些像素格式,UV 是混合存在同一个 plane 里面的。
相关知识推荐阅读《AVPixFmtDescriptor结构》
av_image_fill_max_pixsteps 函数的代码实现如下,函数虽然接受的是参数看起来是一个数组,但其实是指针,编译器会把数组转成指针传进去的。
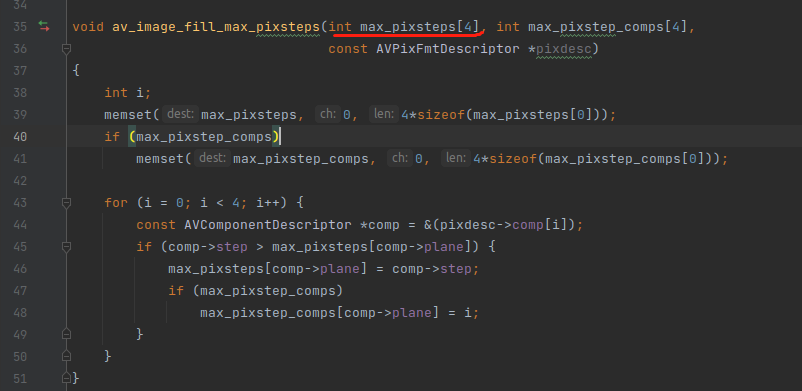
下面用个实际的例子来演示一下 av_image_fill_max_pixsteps 函数的作用,代码如下:
int align_size = av_image_get_buffer_size(AV_PIX_FMT_YUV420P ,300 ,300 ,16);
int align_size2 = av_image_get_buffer_size(AV_PIX_FMT_UYVY422 ,300 ,300 ,16);
下面两张 debug 调试图 比较重要,需要时常翻阅。
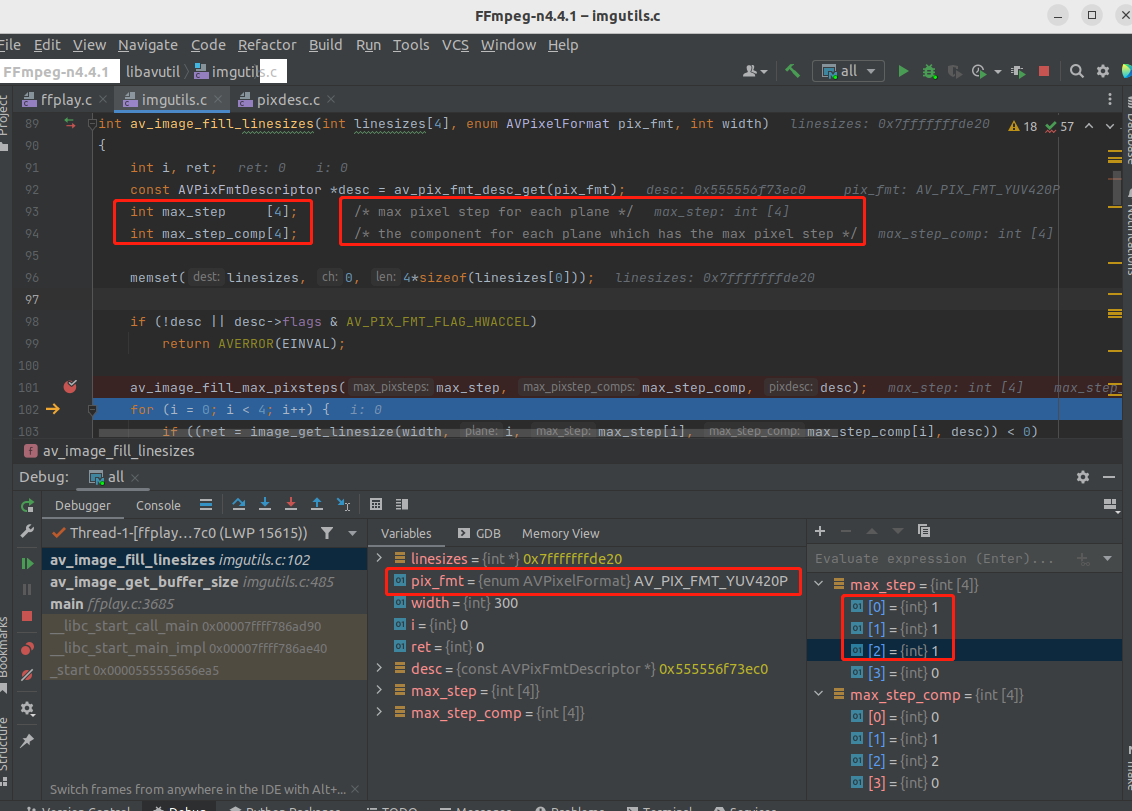
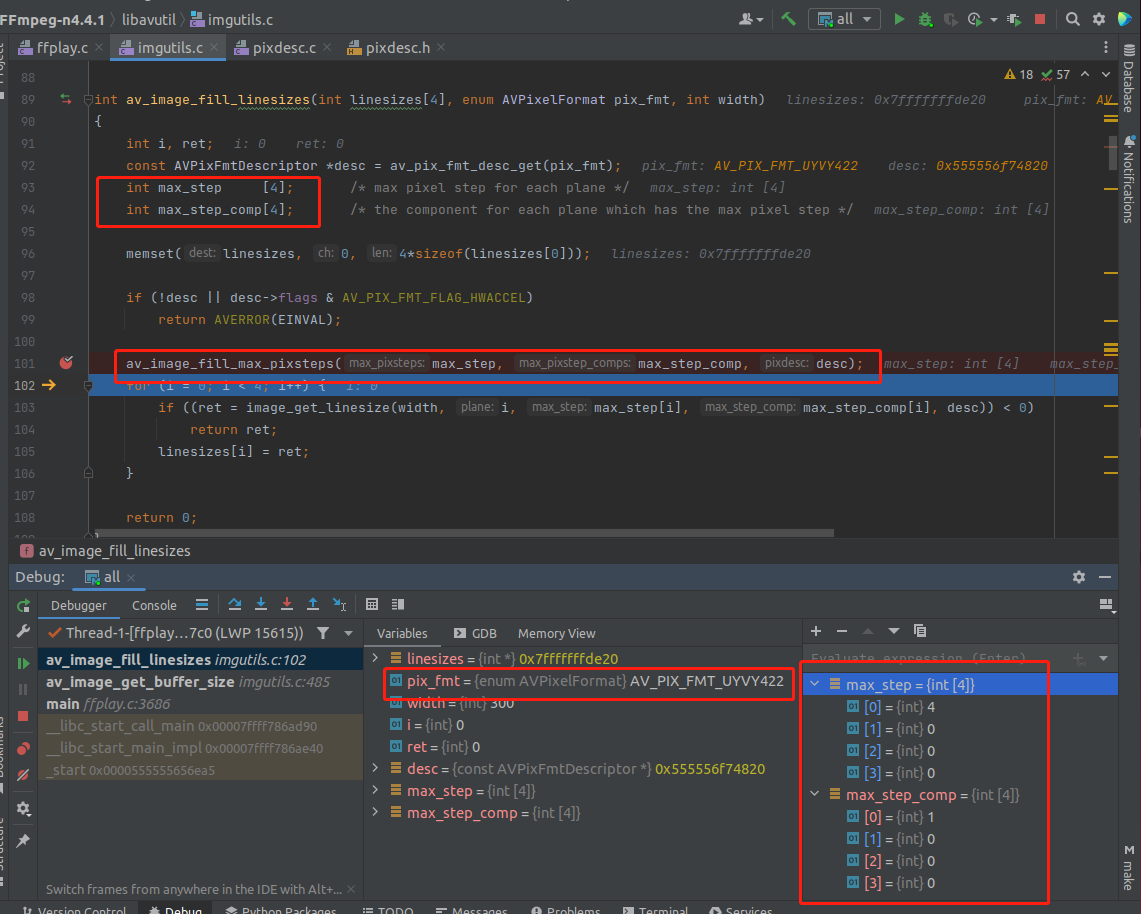
上图中,有两个重要的数组变量,max_step 跟 max_step_comp 。先来逐个解析。
int max_step[4]; /* max pixel step for each plane */
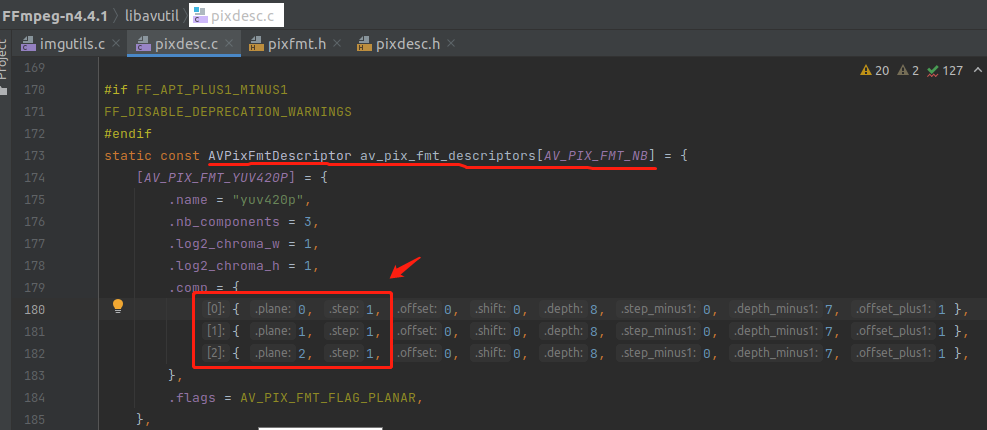
这句英文注释的意思是,max_step 数组存储的是 每个 plane 中最大的 step,AV_PIX_FMT_YUV420P 的 YUV 是独立存放的,也就是放在 3 个 plane 里面,所以 最大 step 就是自己,没有其他的 分量需要比较。如下:
如果是 AV_PIX_FMT_YUYV422 ,他只有 一个 plane,也就是 plane 0 ,所以最大值是 4 。如下:
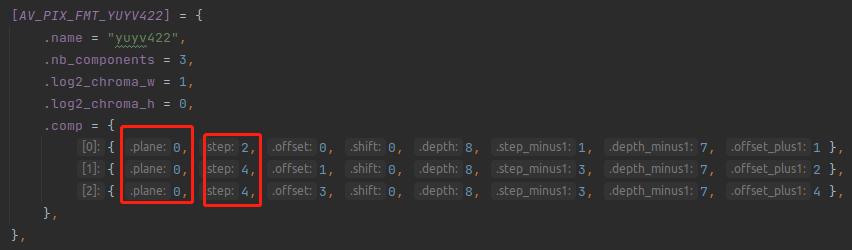
前面的 debug 调试图中,420p 的 max_step 数组是 1,1,1,0。而 422 的 max_step 数组是 4,0,0,0。就是这么算出来的。
再来讲一下 max_step_comp 数组变量。
int max_step_comp[4]; /* the component for each plane which has the max pixel step */
这句注释的意思是这样的,因为可能有 多个 component 存储在 一个 plane 里面,例如 UV 合在一个 plane,他需要知道,最大的那个 step 是来自 U ,还是来自 V 的。也就是 max_step_comp 数组是用来确定 最大的 step 是来自哪个 component 的。
这也就是为什么 上面的 debug 图里面,420P 的 max_step_comp 数组是 0 1 2 0,而 422 的 max_step_comp 数组是 1 0 0 0,因为 422 只有一个 plane,所以只用到 max_step_comp 数组里面的一个元素。
在 422 里面 3 个 component 都在 第 0 个 plane 里面,而且 第 0 个 component 的 step 是 2,第 1 个 component 的 step 是 2, 第 2 个 component 的 step 是 2。
因为 第一 跟 第二 component 的 step 是一样的,所以以第一个为准,所以 422 的 max_step_comp 数组为 1 0 0 0 ,就是这么算出来的。
av_image_fill_max_pixsteps 函数已经讲解完毕,接着讲 image_get_linesize 函数干了什么事情。代码如下:
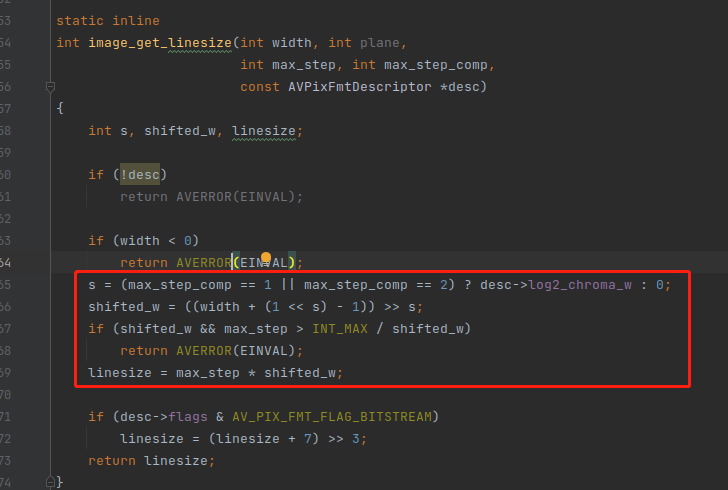
上图的代码中有 3 段逻辑非常重要 :
1,获取 s 变量的值。
s = (max_step_comp == 1 || max_step_comp == 2) ? desc->log2_chroma_w : 0;
变量 s 的全称是 shift (位移)的意思,首先 他 判断 component 是不是 1 跟 2,1/2 代表这是一个 色度 component,色度 分量的数量,可以由 亮度分量 的数量 右移 得到,右移多少位呢?这个就在 desc->log2_chroma_w 里面。
0 本身就是 亮度 component,所以他不需要判断 0 ,只需判断 1 跟 2。如果是 1 或者 2,那这个 component 就属于色度分量。
这里墙裂推荐阅读《AVPixFmtDescriptor结构》,阅读本文的前提是理解 AVPixFmtDescriptor结构
2,计算 shifted_w 变量的值。
shifted_w = ((width + (1 << s) - 1)) >> s;
shifted_w 实际上就是色度的样本数,因为 色度的 样本数样通过 width 位移得到, width 实际上就是亮度样本数的大小。提示:shifted_w 有可能等于 width。
(1 << s) - 1) 这个操作不太容易看懂,但这是 FFmpeg 里面的一个细节,实际上就是向上取整。他这样写跟直接 调 ceil() 函数是一样的。
shifted_w = ceil( width >> s);
不过位移在指令里面是性能最高的,用 ceil 会带来函数调用损耗。这是 FFmpeg 性能优化的细节之处。
提醒:这里取整实际上就是采样取整,亮度右移 1 位就是色度样本数量,但是右移1 就是除以 2,如果一个数不能被 2 整除。就代表色度样本的分配是不均衡的。
不均衡是什么意思,例如 YUV420p 有 401 个亮度样本,他的规则是每 4 个Y 共享一个 UV。多了一个 亮度样本,最后肯定是一个 Y 独享一个 UV,这就是不均衡。
3,计算 linesize 变量的值。
linesize = max_step * shifted_w;
可以看到,他是用了 max_step 直接相乘,在 AV_PIX_FMT_YUV420P 里面 不太容易看出这句代码的真正含义,因为 420p 所有的 component 的 step 都是 1。
所以我们换成 AV_PIX_FMT_UYVY422 来看一下,如下:
分析技巧:要理解这个函数,必须代入实际的场景来分析,实际断点调试一番。
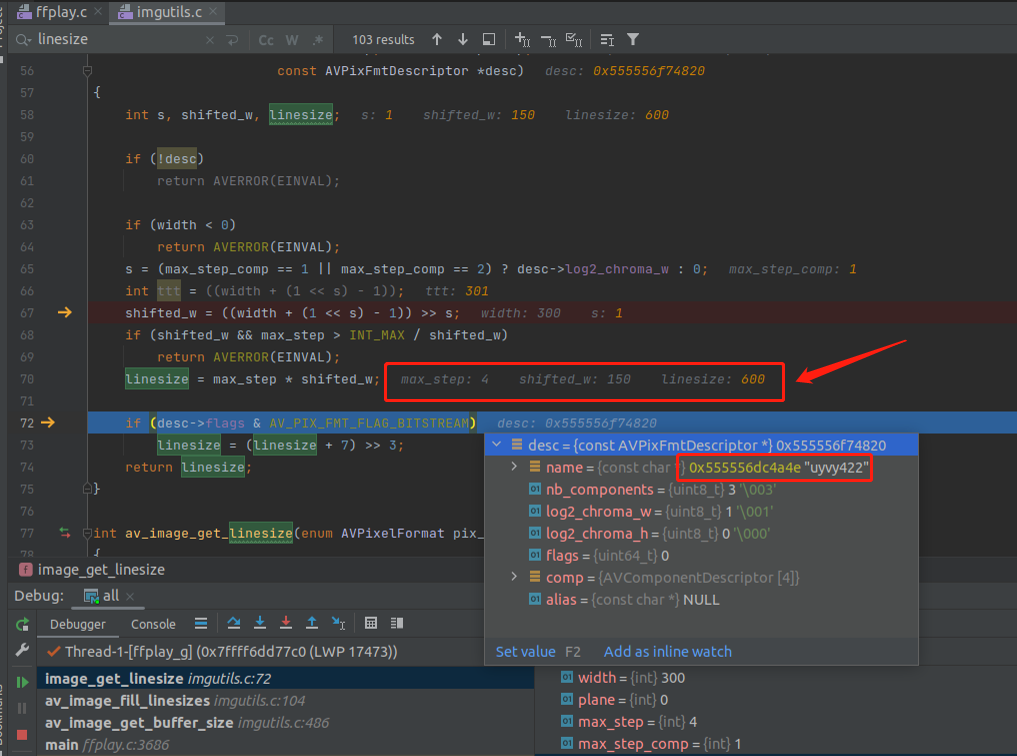
可以看出,linesize 算出来 600。
因此,在 AV_PIX_FMT_YUV420P 跟 AV_PIX_FMT_UYVY422 两种个格式下,av_image_fill_linesizes 函数执行完之后,linesize[4] 数组的值如下:
#AV_PIX_FMT_YUV420P
linesize[4] = {300,150,150,0}
#AV_PIX_FMT_UYVY422
linesize[4] = {600,0,0,0}
再次提醒:linesize[4] 数组 里面存储的是 stride 值,不是样本数。
av_image_fill_max_pixsteps 跟 image_get_linesize 函数都讲解完毕了,那 av_image_fill_linesizes 函数也算讲解完毕了。
下面回到 av_image_get_buffer_size 函数继续讲解,重点如下:
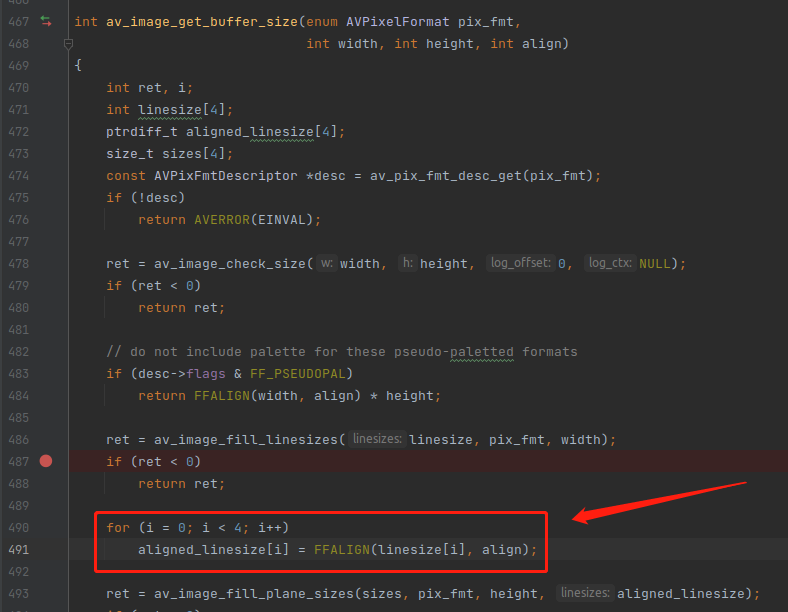
可以看到,在 490 行开始对齐内存 stride 值。
接下来分析,av_image_fill_plane_sizes() 函数,注意在这个函数,会把 高度 丢进去。

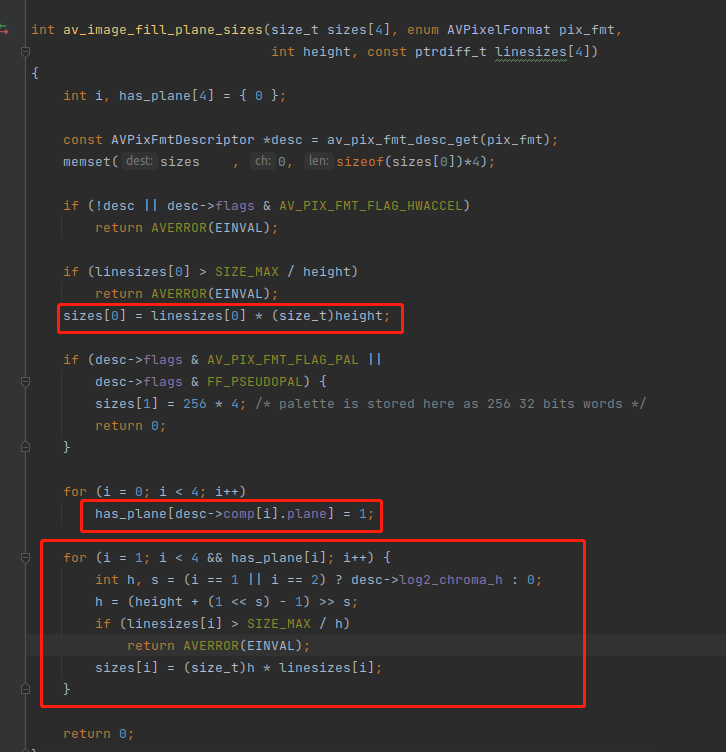
上图已经圈出来了 av_image_fill_plane_sizes() 函数的重点 :
1,sizes[0] 直接就乘以 height。因为 sizes[0] 是亮度分量,他是不需要唯一的。
2,注意最后一个 for 的 i 变量,他是 从 1 开始的。 (height + (1 << s) - 1) >> s 实际上就是位移取整,跟之前类似。
最后 再把位移之后的 h 进行相乘。所以对于 AV_PIX_FMT_YUV420P ,16位 对齐的整个计算过程如下:
size = FFALIGN((width >> log2_chroma_w),16) * (height >> log2_chroma_h)
所以 上面代码中的 sizes[4] 就是全部的大小,因为宽高都用上了,而且只针对宽度进行对齐。
av_image_get_buffer_size() 函数最后就是对 sizes[4] 数组 求和,然后返回。
回到本文最开始的疑问,139200 字节是如何算出来的,计算公式如下:
首先,FFALIGN(300,16) * 300 是亮度分量的,然后 *2 是因为 UV 是一样大小。
300 按 16 字节对齐是 304,300 右移 1 位 等于 150,150 按 16 字节对齐,就等于 160。
因此 av_image_get_buffer_size() 函数的真正作用,他的对齐参数,实际上就是对 width 进行对齐,不会对 height 进行对齐。
本文讲解完毕,再抛另一个问题,内存对齐之后,会多出一些内存,这个会不会影响实际存储的大小。因为 YUV 是需要发给编码器进行编码的,对齐内存之后会不会导致编码器 输出的 AVPacket 的大小也变大了呢?这个请看《FFmpeg内存对齐2》
