audio_decode_frame函数分析—ffplay.c源码分析
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
首先说明一下,audio_decode_frame() 函数跟解码毫无关系,真正的解码函数是 decoder_decode_frame 。
audio_decode_frame() 函数的主要作用是从 FrameQueue 队列里面读取 AVFrame ,然后把 is->audio_buf 指向 AVFrame 的 data。如果 AVFrame 的音频信息跟 is->audio_src 不一致,就会进行重采样。如果进行重采样, is->audio_buf 指针会指向重采样后的内存 audio_buf1,而不是 AVFrame::data。
audio_decode_frame() 函数的流程图如下:

audio_decode_frame() 函数的重点代码如下:
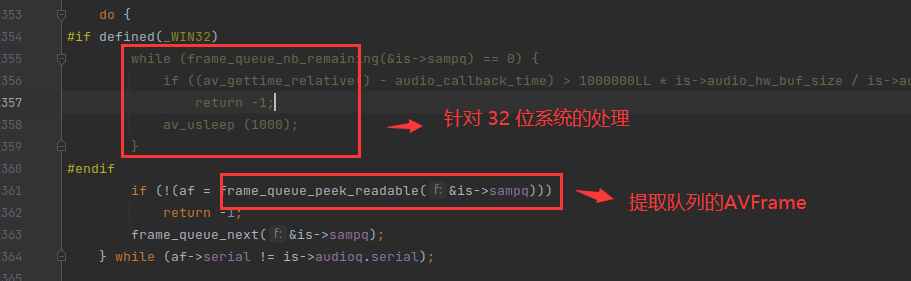
TODO: _WIN32 不是指 32位系统,这里有个错误,后面修复。
从上图可以看到,在提取 FrameQueue 队列的 AVFrame 的时候,会对 32 位的系统做一个处理。这种情况在一些性能差的设备会出现,就是解码线程慢于播放线程,播放线程来取数据的时候,发现队列没有数据可读,这时候,可以最多等等 1/2 的回调时间,在本文的命令里,是 0.04s 执行一次回调函数。
回调间隔的计算方式如下:
回调间隔 = 1000000LL * is->audio_hw_buf_size / is->audio_tgt.bytes_per_sec
上图 除以 2 ,就是 二分之一 的回调间隔。所以在一些老旧设备上,audio_decode_frame() 函数最多会 av_usleep 休眠 0.02s 才返回 -1 ,也就是拿不到数据。
休眠 1/2 的回调时间有什么好处呢?
举个例子,播放的还是 juren-5s.mp4 ,每 0.04s 秒调一次 audio_decode_frame() 函数。
在下午2点(14:00)的时候,SDL 回调了 audio_decode_frame() 函数,因为设备性能差,此刻 FrameQueue 里面没有数据可以拿。14:00:005 的时候才解码出数据放进去 FrameQueue ,解码慢了0.005s。如果 不sleep,立即就返回了 -1。因为下次回调要等 0.04s,返回 -1 就会导致音频设备多播放了 0.04s 的静音数据。也就是说本来应该播放的数据,如果因为解码慢,又不sleep,延迟了0.04s才播放。
如果 进行 av_sleep 就可以在 14:00:005 左右的时刻把数据写进 SDL 的内存,只延迟了0.005s。
提示:av_usleep() 函数的单位是微妙,也就是百万分之一 秒。
拿到 AVFrame 之后,就会计算 AVFrame 里面音频数据的大小(data_size),然后校验一下 声道数 与 声道布局是否一致,最后就是判断是否需要重采样,如下:
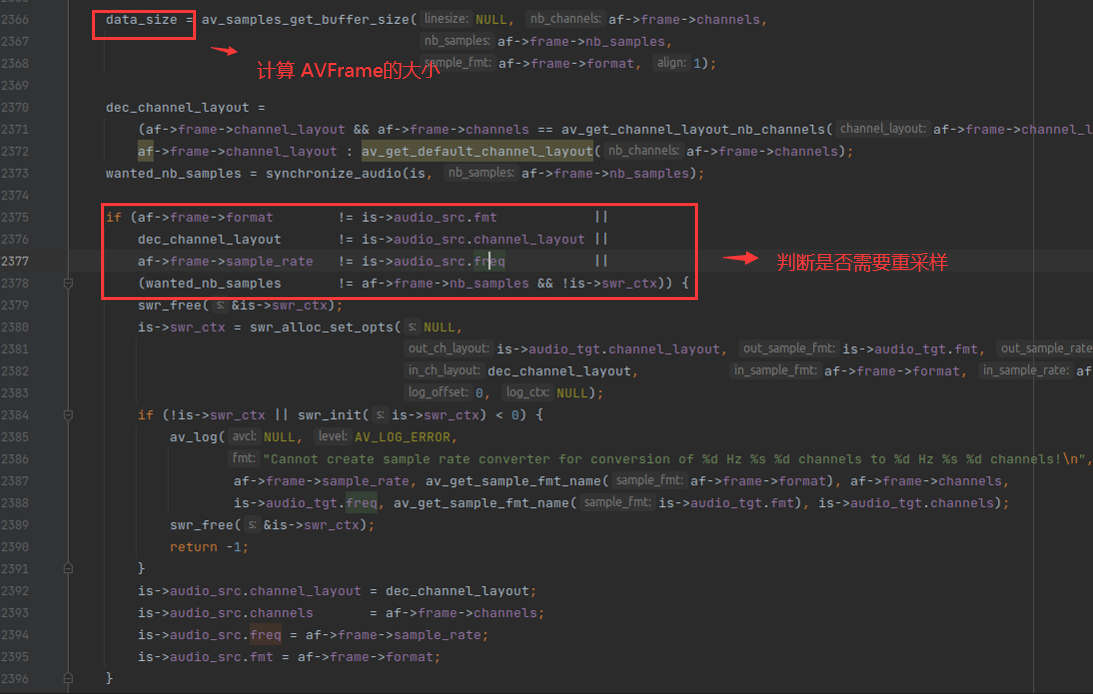
判断是否需要重采样的逻辑是异常复杂的,在分析之前,需要讲解一下 is->audio_src 这个变量的赋值过程,如下:
stream_component_open() 函数
ffplay.c 2671行

从上图可以看到,编译的时候启不启用 CONFIG_AVFILTER(滤镜模块),sample_rate,nb_channels,channel_layout 变量的赋值会不一样。
不启用滤镜模块,sample_rate 等变量就会从解码器实例赋值过来的,因此FrameQueue 存储的是从解码器出来的数据。
启用了滤镜模块,sample_rate 等变量就会从出口滤镜里提取,因此FrameQueue 存储的是从 buffersink 出口滤镜出来的数据。
然后就会尝试用 sample_rate,nb_channels,channel_layout 去打开音频硬件设备。
但是音频设备不一定支持这些采样率跟声道布局,所以可能会做下调整,调整后的格式就放在 audio_tgt 变量里面。
不过基本不会有那么差的音响硬件,大部分情况,audio_tgt 的格式就是跟 sample_rate等变量一样的,一般播放不会进行降低采样率或者调整声道布局。
最后还把 audio_tgt 赋值给 audio_src。
回到 audio_decode_frame() 函数判断是否需要重采样的代码。
if ( af->frame->format != is->audio_src.fmt ||
dec_channel_layout != is->audio_src.channel_layout ||
af->frame->sample_rate != is->audio_src.freq ||
(wanted_nb_samples != af->frame->nb_samples && !is->swr_ctx) ) {
...
创建重采样实例
...
}
注意:上面代码中的 is->audio_src->fmt 音频采样格式是写死成 AV_SAMPLE_FMT_S16 的,所有的数据都会转成 AV_SAMPLE_FMT_S16 再丢给 SDL。
所以一共会有以下 3 种场景需要进行重采样。
1,从 FrameQueue 拿到的 AVFrame 的音频 采样格式 format 不等于 AV_SAMPLE_FMT_S16。
format 不等于 AV_SAMPLE_FMT_S16 有两种情况,一是 MP4 里面音频流的采样格式本身就不是 AV_SAMPLE_FMT_S16,二是 ffpaly 命令行参数使用了滤镜参数改变了 format 采样格式,所以导致 FrameQueue 队列存储的音频采样格式就不是 AV_SAMPLE_FMT_S16 。
2,audio_open() 打开音频硬件设备的时候,对声道布局,采样率进行过调整,导致 is->audio_src 与 af 的采样率,声道布局不一致。
3,用视频时钟为主时钟进行音视频同步,当音视频不同步的时候,就需要减少或增加音频帧的样本数量,让音频流能拉长或者缩短,达到音频流能追赶视频流 或者减速慢下来等待视频流追上来 的效果。也就是最后一个条件, wanted_nb_samples 不等于 af->frame->nb_samples
第三种场景可以不用管,因为基本没人用视频时钟来做同步。
当需要进行重采样的时候,就会创建重采样实例 is->swr_ctx,然后进行重采样操作,如下:

上图中的重点就是 进行 与 不进行重采样,audio_buf 指针指向的地址是不一样的。
不进行重采样,audio_buf 指针指向 af->frame->data[0]。
进行了重采样,audio_buf 指针指向 is->audio_buf1,audio_buf1 可以说是重采样之后的内存。
提示:resampled_data_size 变量也会相应变化。
重采样相关的函数使用请看《音频重采样函数详解》
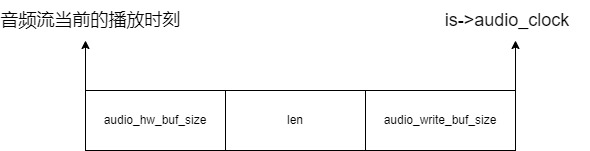
最后,就是设置 is->audio_clock,如下:

is->audio_clock 代表播放完这一帧数据后,音频流的 pts 是多少。这是用来计算音频流当前的 pts 的,如下:
至此,audio_decode_frame() 函数分析完毕。
