FFplay音频同步分析—ffplay.c源码分析
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
本文是讲解当视频时钟设置为主时钟的时候,音视频同步的逻辑。可以通过以下命令设置 视频时钟为主时钟:
ffplay -sync video -i juren-30s.mp4
当视频时钟设置为主时钟的时候,is->av_sync_type 等于 AV_SYNC_VIDEO_MASTER,之前在《FFplay视频同步分析》提到的3处视频同步的代码,全部都会失效,如下:
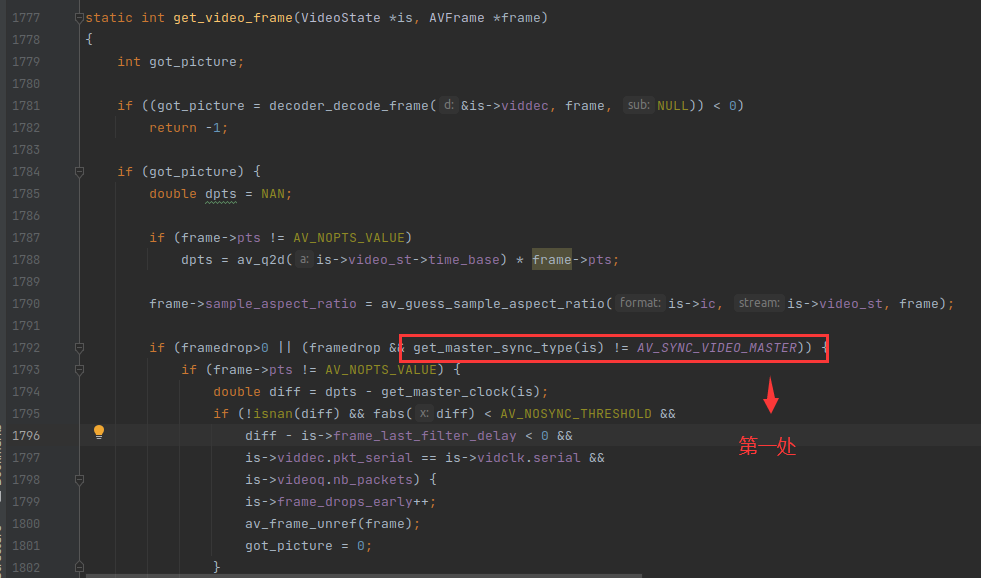
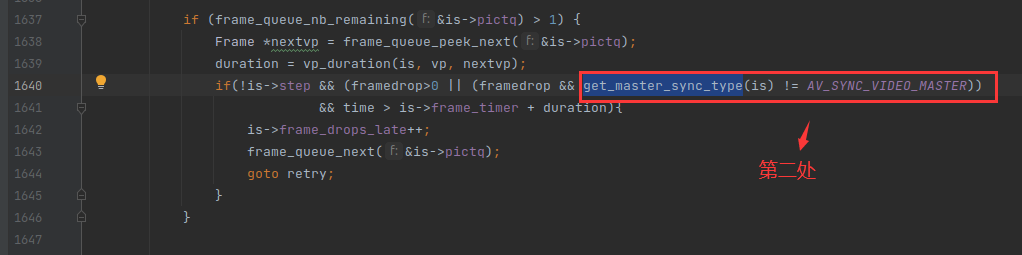
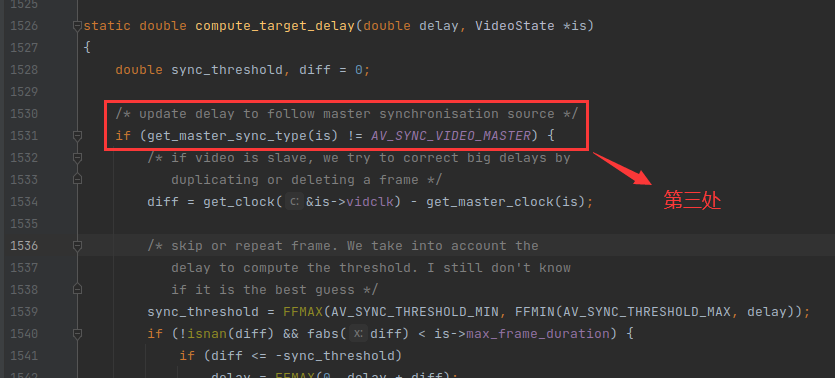
因此当视频是主时钟的时候,视频流永远不会丢帧,即使视频播放线程卡顿,也不会丢帧。不过如果视频播放线程卡顿,可能会导致某些帧的播放时长缩短。因为一般情况是 0.01s 检查一次,如果卡顿,导致视频播放比预定的时间慢了0.12s,通常一帧的播放时长是0.04s。所以慢了 3 帧,因此这3帧会在0.03s内播放完毕。
当视频时钟设置为主时钟的时候,音频同步的逻辑就会生效,音频同步的逻辑是在 audio_decode_frame() 函数里面的,如下:

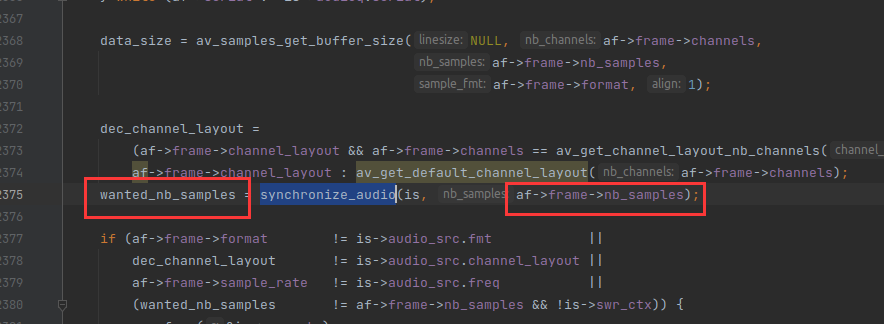
synchronize_audio() 函数就是用来实现音频同步逻辑的。af->frame->nb_samples 代表 AVFrame 原来的样本数,而 wanted_nb_samples 代表 AVFrame 调整之后的样本数,通常会增加样本数或者减少样本数。
synchronize_audio() 函数的重点代码如下:
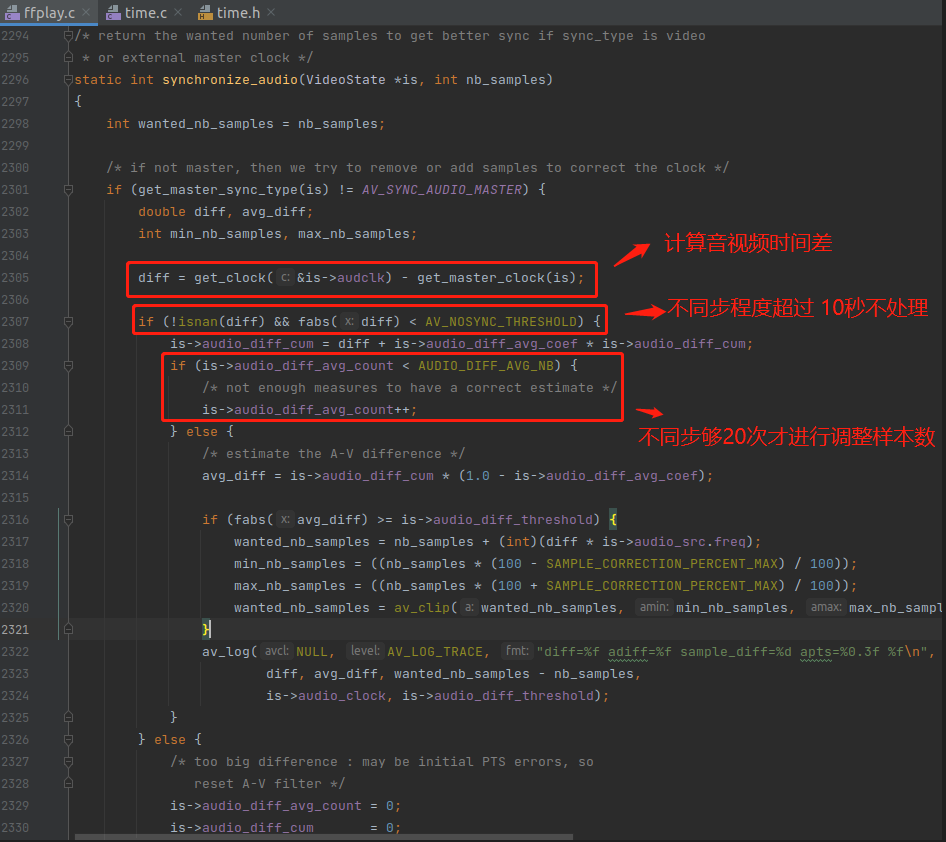
synchronize_audio() 函数的音频同步算法也是类似的套路,如果超过 AV_NOSYNC_THRESHOLD(10s) 就不处理,跟之前《FFplay视频同步分析》里面的视频同步逻辑一样。
音频同步算法也是把不同步的程度控制在阈值(audio_diff_threshold)内,如果不超过阈值 就不进行同步了。
synchronize_audio() 函数的音频同步算法有点复杂,主要涉及到两个数学概念。
1,加权平均数
2,等比数列
他的整一个逻辑就是取 20次以上的音视频差异,累加到一起,形成加权总和。
每次音视频的差异的权重是不一样的,例如 a ~ z 一共 24 次音视频差异,a 是第1次差异的值,z 是第 24 次差异的值。
那 a 的权数 是小于 b 的权数的,b 又小于 c ,以此类推。最近一次,也就是 z 的权数 是 1。
然后再求 20次以上的加权总和的加权平均数,而 加权平均数 的公式如下:
加权平均数 = 加权总和 / 权数总和
而权数总和是一个等比数列。
下面介绍一下 synchronize_audio() 函数里面的一些变量的作用。
1,AV_NOSYNC_THRESHOLD,这个宏是 10,单位是秒,所以如果差异太大,超过10s,直接不调整样本数,跟之前《FFplay视频同步分析》里面的视频同步逻辑一样,都是超过 10s 不进行同步。
2,AUDIO_DIFF_AVG_NB,这是一个数量值,值为 20,这个其实是取 20 次以上的音视频差异来计算 加权平均数。越前面的差异时间权重越大。例如 第 21 次的音视频时间差异 的权重大于 第 20 次的权重,第 20 次的权重大于 第 19 次的权重。
在 ffplay.c 里面,加权平均数就是 avg_diff 变量,下面会讲到。
3,is->audio_diff_avg_coef,这个变量实际上是 等比数列 里面的 公比q ,代码如下:
is->audio_diff_avg_coef = exp(log(0.01) / AUDIO_DIFF_AVG_NB);
上面的代码其实是求 什么样的一个数 连续乘以自身 20 次 后等于 0.01,计算出来是 0.79432,所以 audio_diff_avg_coef 等于 0.79432。
4,is->audio_diff_cum,这是20次音视频差异的加权总和,代码如下:
is->audio_diff_cum = diff + is->audio_diff_avg_coef * is->audio_diff_cum;
可以看到,audio_diff_cum 每次累加 diff 之前,之前的累计值都会乘以 audio_diff_avg_coef,这是什么意思呢?
其实这是一种降权的操作,主要作用是让前面的差异权重越来越小,后面的差异权重越来越大。我把 diff 分为 3 次差异讲解。
a_diff 为第一次差异,b_diff 为第二次差异,c_diff 为第三次差异。
is->audio_diff_cum = c_diff * 1 + ((b_diff + (a_diff * 0.79432) ) * 0.79432)
可以看到,最开始的差异 a_diff 乘了两次 0.79 ,所以 a_diff 会变得越来越小,b_diff 乘了一次 0.79432,c_diff 还是原来的 c_diff ,c_diff 的权重最大,是 1。
假设现在已经有 24 次音视频时间不同步了,a ~ z 一共 24 次,a 代表第一次,z 代表第 24 次。这时候 is->audio_diff_cum 实际上就等于下面的算法。
is->audio_diff_cum =
a * (0.79 ^ 23) +
b * (0.79 ^ 22) +
c * (0.79 ^ 21) +
d * (0.79 ^ 20) +
....
z * (0.79 ^ 0)
提示1:如果0.79 连续乘以自身 20 次之后,权重就会小于 0.01 ,几乎可以忽略不计。
提示2:任何数的 0 次方都是 1 ,所以 (0.79 ^ 0) = 1。
从上面可以看出来, is->audio_diff_cum 是多次音视频差异的加权总和,如果想求它的加权平均数,还需要除以权数总和,权数总和就是每次音视频差异的权数加起来,如下:
我用 w 字母表示权重总和,因为 gitbook 这个数学插件他不支持中文。
可以看出来,权数总和是一个等比数列,等比数列的求和公式如下:
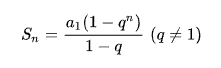
a1 是首项,所以 a1 等于 1。而 q^n 是 0.79 乘以 20 次以上的值,可以忽略不计。
因此,整个权数总和实际上就如下:
因此 avg_diff (加权平均数)的计算过程如下:
所以就产生了下面这行代码:
avg_diff = is->audio_diff_cum * (1.0 - is->audio_diff_avg_coef);
avg_diff 就是20 次以上的音视频差异的加权平均数。
6,is->audio_diff_threshold,音频同步阈值,音视频不同步的程度超过这个值,就会进行干预。计算方式如下:
/* since we do not have a precise anough audio FIFO fullness,
we correct audio sync only if larger than this threshold */
is->audio_diff_threshold = (double)(is->audio_hw_buf_size) / is->audio_tgt.bytes_per_sec;
可以看到,is->audio_hw_buf_size 等于一次回调要取的数据量,所以 audio_diff_threshold 等于音频 sdl_audio_callbacl() 的回调间隔。
注意,音视频同步阈值是一次回调的时间间隔,而不是一帧音频的播放时长。
通常情况,audio_diff_threshold 等于 0.04s。
计算出来 avg_diff 跟 audio_diff_threshold 之后,就可以进行同步操作了。
当 加权平均数 大于 音频同步阈值,就会进行样本数的调整,调整逻辑如下:
if (fabs(avg_diff) >= is->audio_diff_threshold) {
wanted_nb_samples = nb_samples + (int)(diff * is->audio_src.freq);
min_nb_samples = ((nb_samples * (100 - SAMPLE_CORRECTION_PERCENT_MAX) / 100));
max_nb_samples = ((nb_samples * (100 + SAMPLE_CORRECTION_PERCENT_MAX) / 100));
wanted_nb_samples = av_clip(wanted_nb_samples, min_nb_samples, max_nb_samples);
}
可以看到,调整样本数的时候,用的是当前的音视频时间差(diff),而不是加权平均数(avg_diff)。
而 SAMPLE_CORRECTION_PERCENT_MAX 宏的值为 10,所以替换之后如下:
if (fabs(avg_diff) >= is->audio_diff_threshold) {
wanted_nb_samples = nb_samples + (int)(diff * is->audio_src.freq);
min_nb_samples = ((nb_samples * 0.9);
max_nb_samples = ((nb_samples * 1.1);
wanted_nb_samples = av_clip(wanted_nb_samples, min_nb_samples, max_nb_samples);
}
这是为了每次调整样本数,不能把 AVFrame 的样本数减少或者增加超过 10%,因为音频的连续性很强,调整幅度太大,耳朵容易察觉到。
做下小总结,音频同步的逻辑就是,取 20 次以上的音视频差异 来求 加权平均数(avg_diff),如果 加权平均数 大于 音频同步阈值(audio_diff_threshold),就调整样本数量。
计算出 wanted_nb_samples 之后,会通过 swr_set_compensation() 函数进行重采样,如下:
if (wanted_nb_samples != af->frame->nb_samples) {
if (swr_set_compensation(is->swr_ctx,
(wanted_nb_samples - af->frame->nb_samples) * is->audio_tgt.freq / af->frame->sample_rate,
wanted_nb_samples * is->audio_tgt.freq / af->frame->sample_rate) < 0) {
av_log(NULL, AV_LOG_ERROR, "swr_set_compensation() failed\n");
return -1;
}
}
上面的 is->audio_tgt.freq / af->frame->sample_rate 操作是为了进行采样率单位转换,audio_tgt.freq 是打开的喇叭的音频采样率,可能跟 AVFrame 的不一样。
重采样相关的函数请阅读《音频重采样函数详解》
之前在《sdl_audio_callback音频播放线程分析》说过,音频其实有 3 块内存等待播放,而音视频同步跳转的只是后面两块内存,如下:
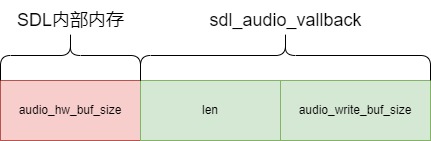
由于红色的 audio_hw_buf_size 是 SDL 内部的内存,没有接口操作,所以 audio_decode_frame() 进行音频同步的时候,操作的是 绿色 的 len + audio_write_buf_size。
无论是拉长或缩短绿色部分内存,还是红色部分内存,达到的效果是差不多的。但是我个人觉得,如果操作红色的内存,音频同步会更加实时。
但是由于音频连续性很强,操作绿色的内存也可以,这种情况,我称为 样本补偿右移,本来应该操作左边红色的内存,但是SDL没有接口可以操作,只能操作右边绿色的内存。
至此,音频同步逻辑分析完毕。
