stream_component_open函数分析—ffplay.c源码分析
作者:罗上文,微信:Loken1,公众号:FFmpeg弦外之音
stream_component_open() 函数主要作用是打开 音频流或者视频流 对应的解码器,开启解码线程去解码。
流程图如下:
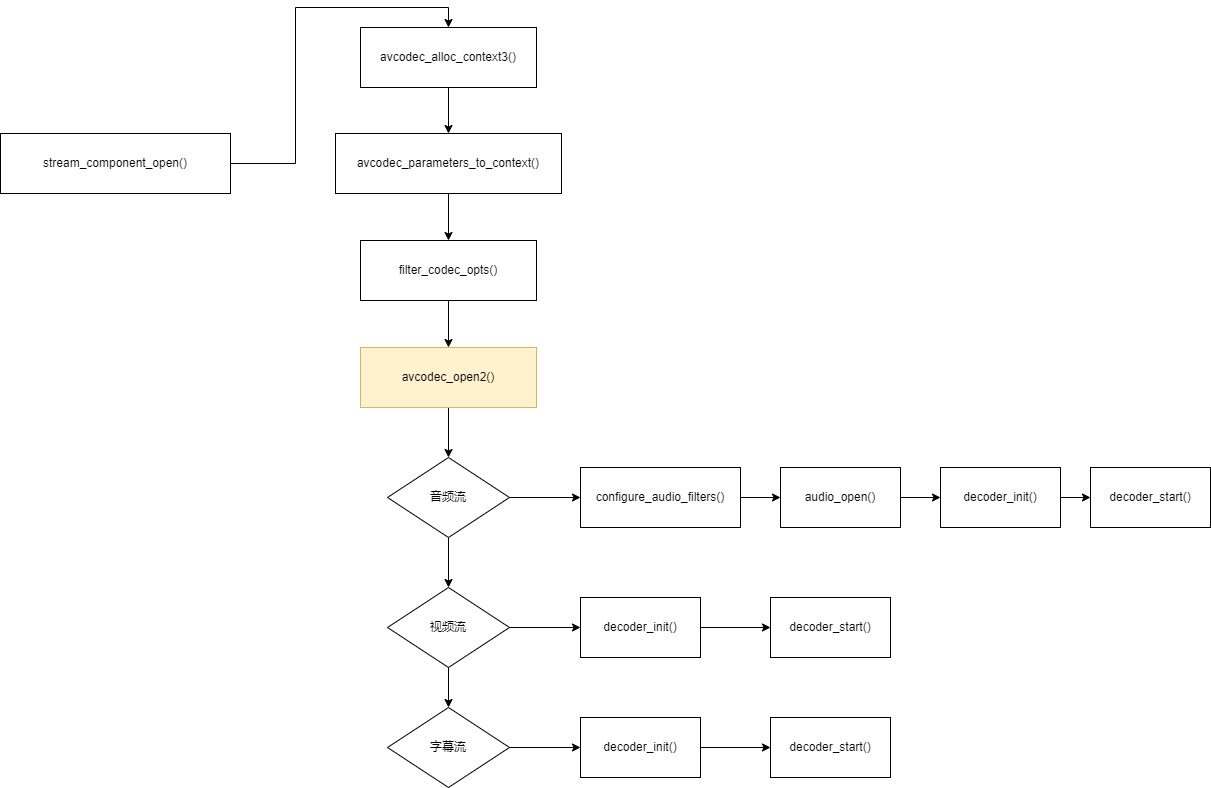
stream_component_open() 的函数定义如下:
/* open a given stream. Return 0 if OK */
static int stream_component_open(VideoState *is, int stream_index)
可以看到,函数的参数非常简单,第一个参数是 VideoState *is 全局管理器,第二个参数 stream_index 是 数据流 的索引值。
下面来分析 stream_component_open() 的函数里面的重点代码:
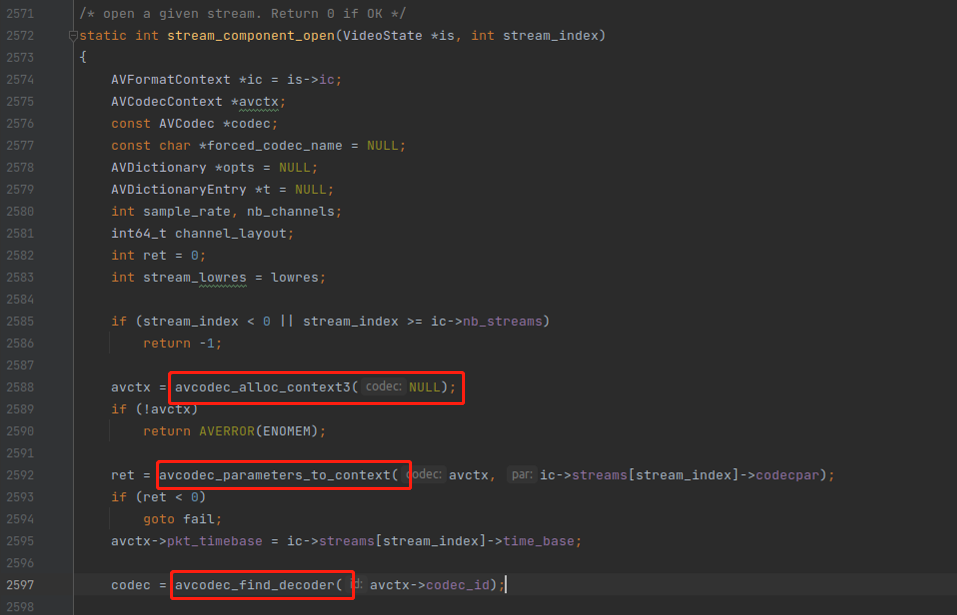
一开始的 avcodec_alloc_context3() 跟 avcodec_parameters_to_context() ,这可以说是常规操作了,就是申请一个解码器实例的内存,然后把容器流里面的信息拷贝过去。容器里面通常都是有编码器信息的。如果不理解这两个函数的作用,推荐阅读《如何使用FFmpeg的解码器》
第二个重点是,使用指定的编码器,例如你不用想 libx264 编码器,而是使用 openh264 编码器,就可以用 -c:v openh264 参数指定编码器。如下:
ffplay -c:v openh264 juren.mp4
也有另一种情况,就是容器里面记录的编码器信息是错误的,而你又知道正确的编码器信息,就可以强制指定。命令行的参数会赋值给 forced_codec_name 变量。命令的参数解析过程推荐阅读《FFplay命令行解析过程》
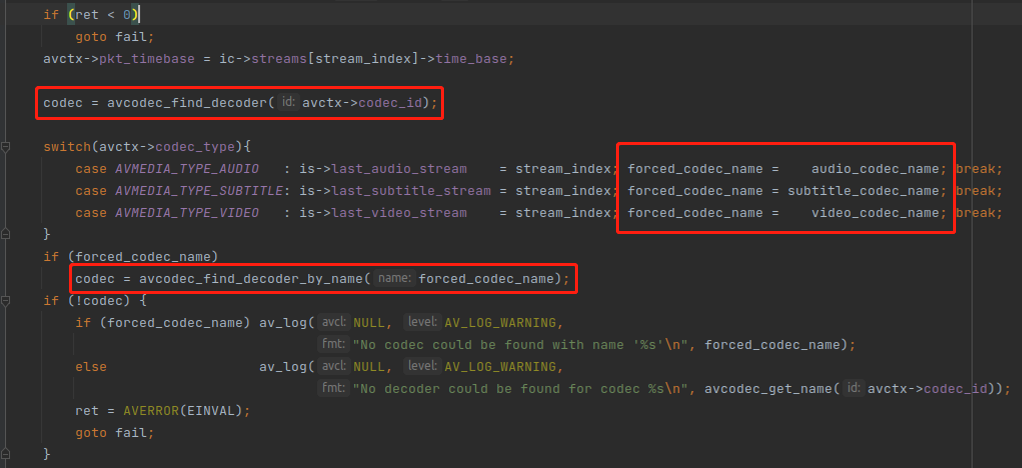
第三个重点,只有两个函数,filter_codec_opts() 跟 avcodec_open2() 。
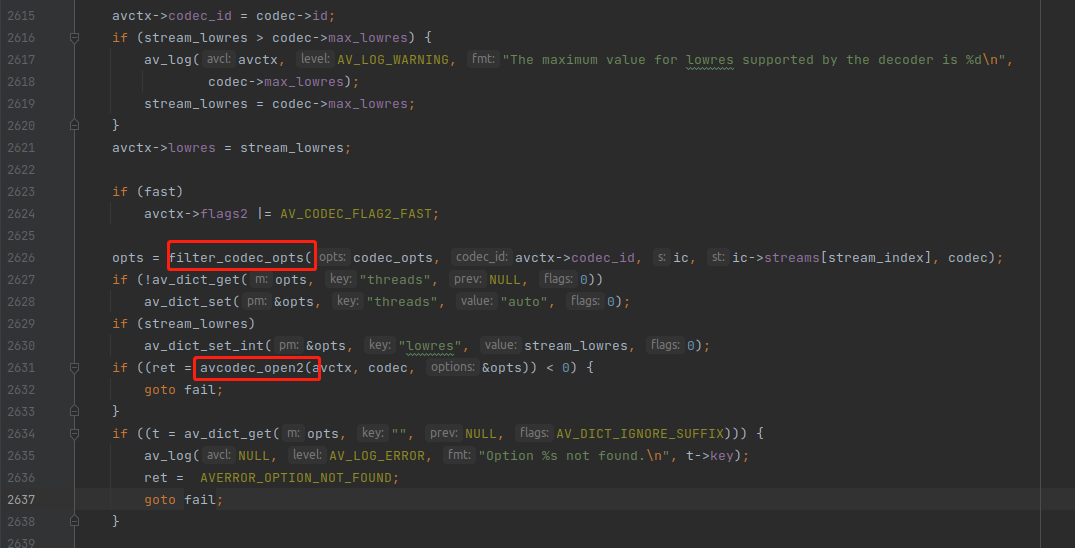
filter_codec_opts() 这个函数实际上就是把命令行参数的相关参数提取出来。举个例子:
ffpaly -b:v 2000k -i juren-5s.mp4
上面的命令,指定了解码器的码率,但是他指定的是视频的码率,当 stream_component_open() 打开视频流的时候,这个 码率参数才会被 filter_codec_opts() 提取出来。
而stream_component_open() 打开音频流的时候,b:v 不会被提取出来,因为这个参数是跟 视频流 相关的。
所以你可以把 filter_codec_opts() 看成是一个处理命令行参数的函数,提取相关的参数。至于什么是相关,可以自行看这个函数的内部实现。
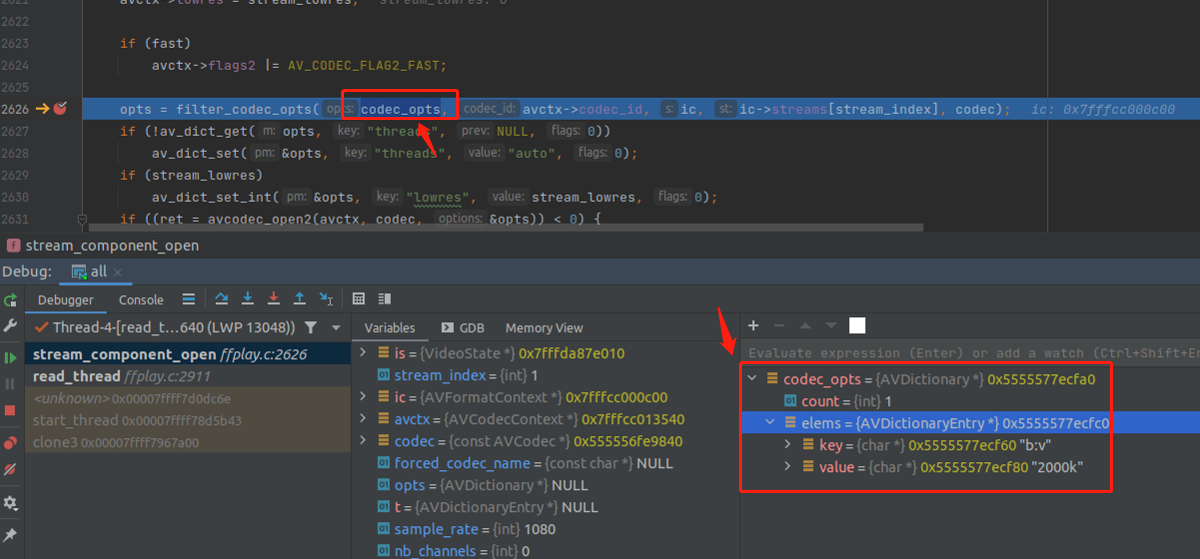
然后 avcodec_open2() 就会接受 filter_codec_opts() 返回 的 AVDictionary 参数。推荐阅读《如何设置编码器参数》
至此,解码器参数已经设置完毕,解码器也已经打开了了。
第四个重点是 把流属性设置为不丢弃, 就是下面这一句代码。
ic->streams[stream_index]->discard = AVDISCARD_DEFAULT;
可以看到,stream_component_open() 函数会把打开的流的 discard 设置为 AVDISCARD_DEFAULT,这样这个流的数据就可以从 av_read_frame() 函数里面读出来了。
注意,ffplay.c 之前 在 read_thread() 函数里面,是把所有的流都设置为了 AVDISCARD_ALL,也就是会丢弃所有流的数据包。
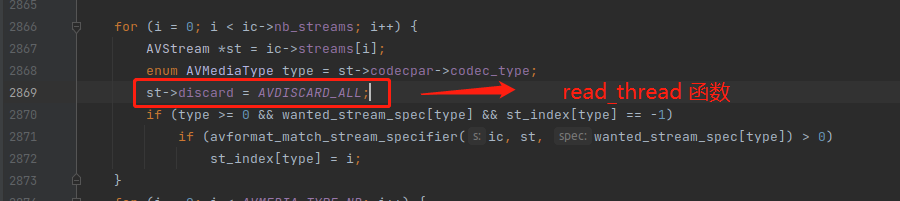
所以,如果 mp4 里面有多个视频流,av_read_frame() 只会读取最好的那个视频流的包,音频流同理。
最后一个重点,就是一个 switch case 的逻辑,如下:
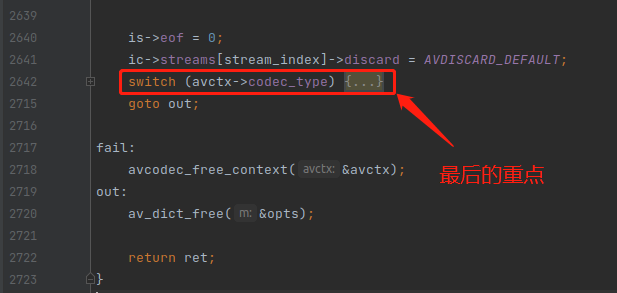
这段代码非常多,所以我把它缩进了。这里分别对 音频,视频,字幕做了区别处理。但是可以看到,音频的逻辑代码明显是最多的。
下面开始分析重点,如下:
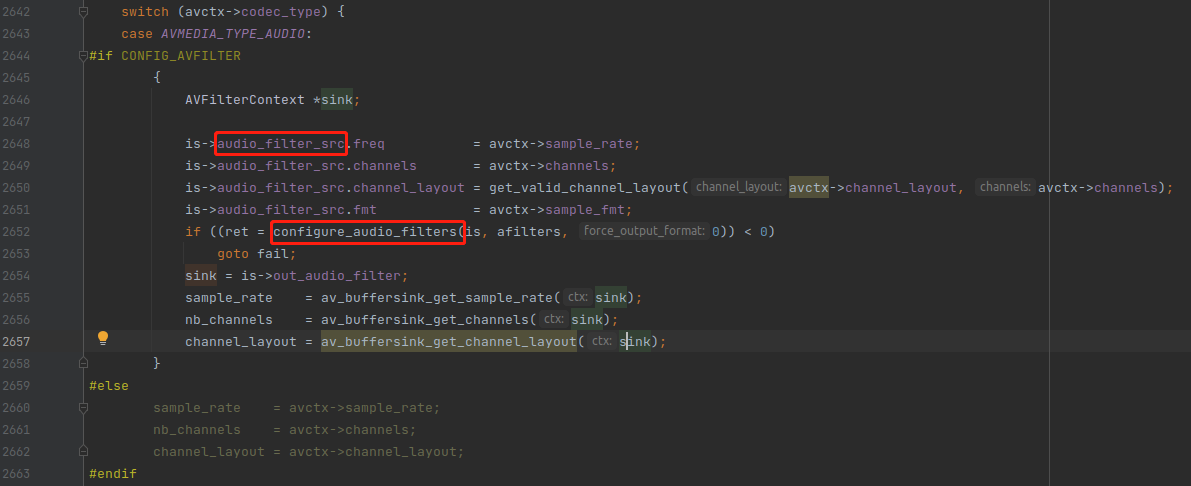
首先可以看到,他有一个宏判断,大部分情况 AVFILTER 滤镜模块都是启用,所以不用管第二个 else。这里需要注意一下,虽然 ffplay -i juren-5s.mp4 这条命令没有使用滤镜,但是 ffplay 的逻辑还是会创建滤镜实例的,只不过这是一个空的实例。这样做是为了代码逻辑更加通用。
无论命令行参数使不使用滤镜,他都是同样的逻辑。
然后需要注意上图中的 is->audio_filter_src 变量,这个变量存储的实际上是从解码器出来的音频信息。然后调 configure_audio_filters() 这个函数来创建音频流的滤镜。
configure_audio_filters() 函数最重要的地方就是搞好了 is->in_audio_filter 跟 is->out_audio_filter 两个滤镜。解码器输出 AVFrame 之后需要往 in_audio_filter 里面丢,然后播放的时候,需要从 out_audio_filter 读取 AVFrame。
configure_audio_filters() 函数的分析请看《FFplay音频滤镜分析》一文。
后面的av_buffersink_get_sample_rate() 等函数的调用实际上就是从 buffsink 出口滤镜里面获取到最后的音频信息。
第二个重点如下:
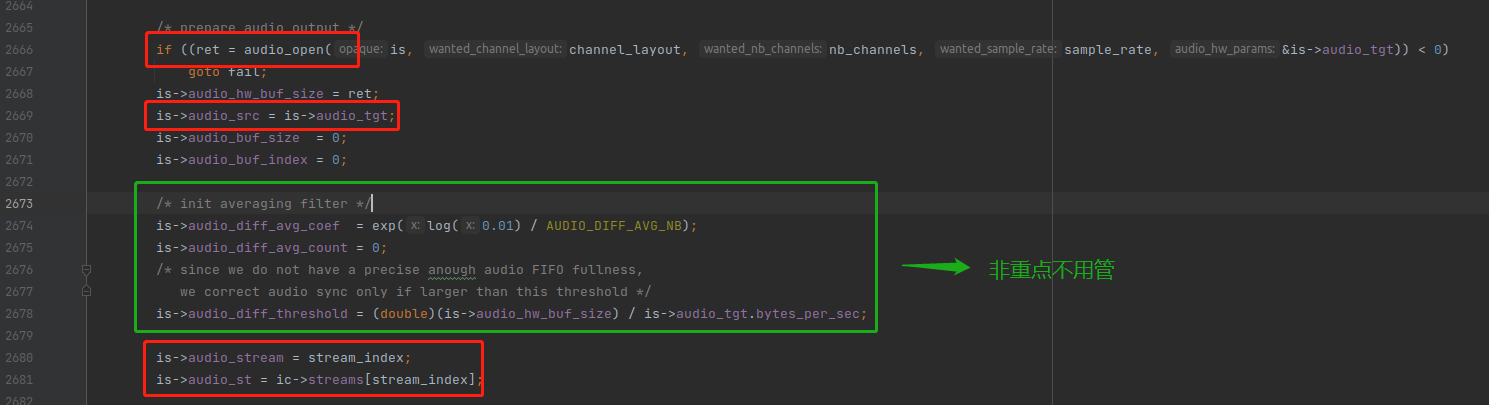
上图中,红色圈是重点,绿色圈不是重点,绿色圈出来的变量 是用在 音频向视频同步的场景上的,非常难懂,而且应用场景极少。通常音视频同步都是以音频时钟为准。所以这段代码可以暂时不管,音频向视频同步这东西你学了基本也用不上,不过可以用来装下逼。
audio_open() 函数的内部逻辑就是调 SDL_OpenAudioDevice() 打开音频设备,不过由于音频设备各种各样,从 buffersink 滤镜出来的音频帧,不一定被硬件设备支持,所以可能需要降低采样率之类。例如:有些比较差的音响不支持太高采样或者太多的声道数。
audio_open() 函数会选出被硬件设备支持的采样率,声道数 去打开。这些最终的声道数,采样率等信息,就放在 is->audio_tgt 变量返回。
所以 audio_open() 函数的重点是,打开音频设备,并且把最终的音频信息放在 is->audio_tgt 变量里面了。
更详细的分析请阅读《audio_open函数分析》
接着,会把 audio_tgt 拷贝给 audio_src,如下:
is->audio_src = is->audio_tgt;
这句代码看起来会有点莫名其妙,为什么把 audio_tgt 赋值给 audio_src 呢?
首先 is->audio_src 是一个 struct AudioParams ,一个存储音频格式信息的结构体。变量名里有个 src ,代表音频的源头,也就是音频源头的格式是怎样的。但是注意这个源头不是指 MP4 文件里面的音频格式,虽然这个也是源头。
但是它的 src 指的是 is->swr_ctx 重采样实例的源头,也就是当需要进行重采样的时候,要输入给 is->swr_ctx 的原始音频格式就是 is->audio_src。流程图如下:
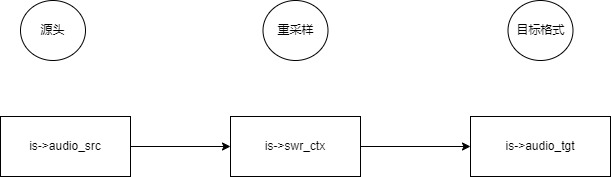
上面的流程图看起来比较容易理解,这是需要重采样的流程,但是不一定总是需要重采样的,当 buffersink 出口滤镜出来的音频格式,跟打开硬件设备时候的音频格式(is->audio_tgf)一致的时候,就不需要重采样了。
上面的流程图,如果去掉重采样,是不是就直接是 is->audio_src = is->audio_tgt; 了?
因此 is->audio_src 存储的其实是 buffersink 出口滤镜的音频格式,但是因为出口滤镜的音频格式可能跟 is->audio_tgt 本身是一样的,所以它上面那句代码就这样写了。
buffersink 跟 audio_tgt 音频格式不一样,就需要重采样。从重采样实例 is->swr_ctx 角度来看, is->audio_src 确实是源头。只是他的代码取巧了一下。
先剧透一下后面 audio_decode_frame() 函数中的重采样代码,如下:
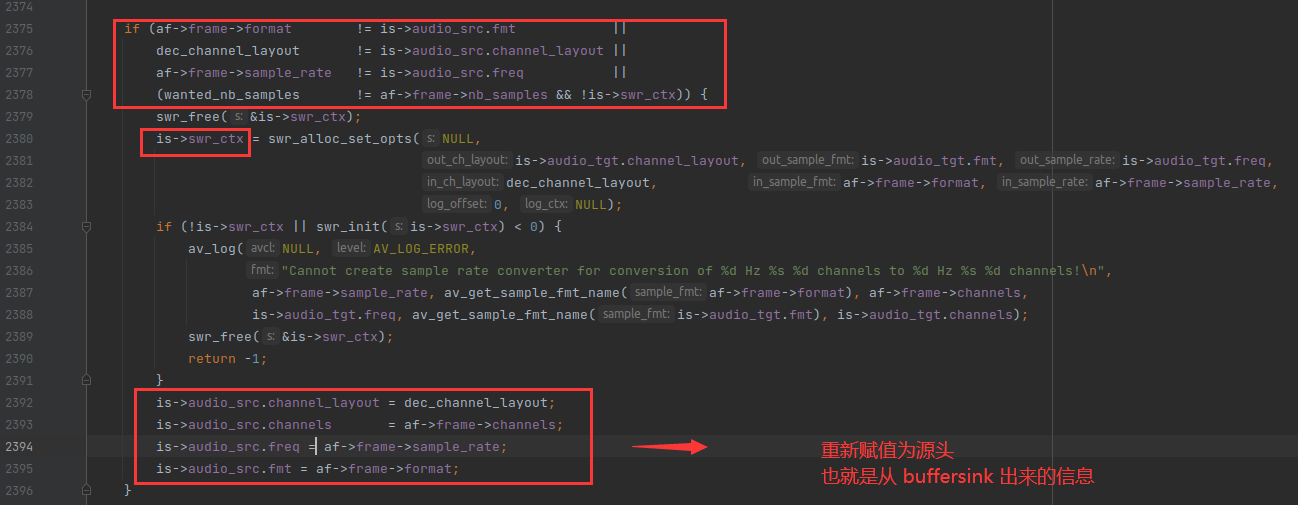
小总结:ffplay 有两个处理音频的地方,一个是 滤镜(is->agraph),一个是重采样(is->swr_ctx)。
最后,就是记录播放的音频流信息,其他的视频流,字幕流也有类似的操作,如下:
is->audio_stream = stream_index;
is->audio_st = ic->streams[stream_index];
最后一个重点就是调用 decoder_init() 与 decoder_start(),如下:
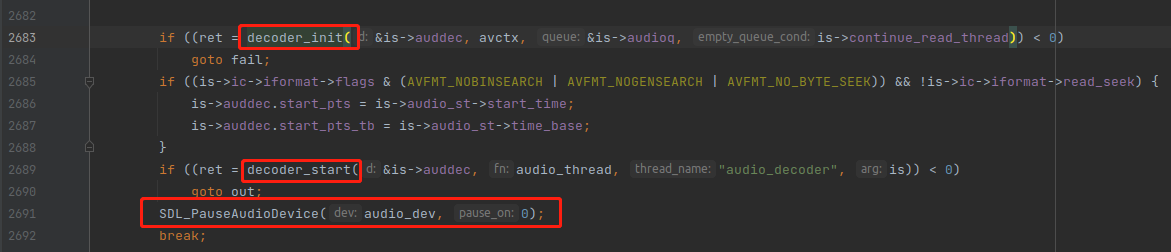
decoder_init() 函数是比较简单的,不过它用了一个新的数据结构 struct Decoder,所以我们先讲一下这个结构,如下:
typedef struct Decoder {
AVPacket *pkt; //要进行解码的 AVPacket,也是要发送给解码器的 AVPacket
PacketQueue *queue; // AVPacket 队列
AVCodecContext *avctx; //解码器实例
int pkt_serial; //序列号
int finished; //已完成的时候,finished 等于上面的 pkt_serial。当 buffersink 输出 EOF 的时候就是已完成。
int packet_pending; //代表上一个 AVPacket 已经从队列取出来了,但是未发送成功给解码器。未发生成功的会保留在第一个字段 pkt 里面,下次会直接发送,不从队列取。
SDL_cond *empty_queue_cond; //条件变量,AVPacket 队列已经没有数据的时候会激活这个条件变量。
int64_t start_pts; //流的第一帧的pts
AVRational start_pts_tb; //流的第一帧的pts的时间基
int64_t next_pts; //下一帧的pts,只有音频用到这个 next_pts 字段
AVRational next_pts_tb; //下一帧的pts的时间基
SDL_Thread *decoder_tid; //解码线程 ID。
} Decoder;
我讲解讲一下 struct Decoder 结构的一些字段,首先是第一个 AVPacket *pkt ,这个实际上就是从 AVPacket 队列拿出来的。然后把这个 pkt 发送给解码器,如果发送成功,那当然是 unref 这个 pkt,但是如果发送给解码器失败,就会把 packet_pending 置为1,pkt 不进行 unref,下次再继续发送。
pkt_serial 这个序列号,推荐阅读《FFplay序列号分析》。
还有一个需要讲解的是 next_pts 字段,一些读者可能会疑惑,不是每一个 AVFrame 都有 pts 的吗? 为什么还需要这个 next_pts 这个字段?
这就是因为解码出来的 AVFrame 的 pts 有些是 AV_NOPTS_VALUE,这时候就需要 next_pts 来纠正。
next_pts 的计算规则就是上一帧的 pts 加上他的样本数(也就是播放多久)。
注意:视频流没有使用 next_pts 来纠正,只有音频流用了 next_pts,如下:
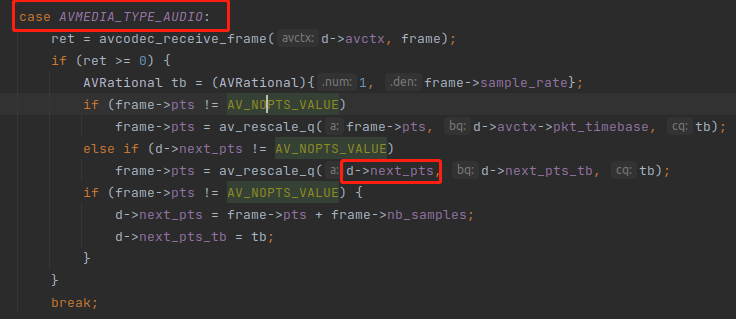
接下来分析decoder_init() 函数,代码如下:
static int decoder_init(Decoder *d, AVCodecContext *avctx, PacketQueue *queue, SDL_cond *empty_queue_cond) {
memset(d, 0, sizeof(Decoder));
d->pkt = av_packet_alloc();
if (!d->pkt)
return AVERROR(ENOMEM);
d->avctx = avctx;
d->queue = queue;
d->empty_queue_cond = empty_queue_cond;
d->start_pts = AV_NOPTS_VALUE;
d->pkt_serial = -1;
return 0;
}
可以看到,就是做一些赋值,比较简单,但是也有一个重点,就是他的 empty_queue_cond 实际上就是 continue_read_thread,只是换了个名字。

接着分析下一个函数 decoder_start(),代码如下:
static int decoder_start(Decoder *d, int (*fn)(void *), const char *thread_name, void* arg)
{
packet_queue_start(d->queue);
d->decoder_tid = SDL_CreateThread(fn, thread_name, arg);
if (!d->decoder_tid) {
av_log(NULL, AV_LOG_ERROR, "SDL_CreateThread(): %s\n", SDL_GetError());
return AVERROR(ENOMEM);
}
return 0;
}
比较简单,就是开启 SDL 解码线程。
至此,switch case 里面对于音频的处理就讲解完毕,对于视频的处理更加简单,仅仅调了 decoder_init() 与 decoder_start(),如下:
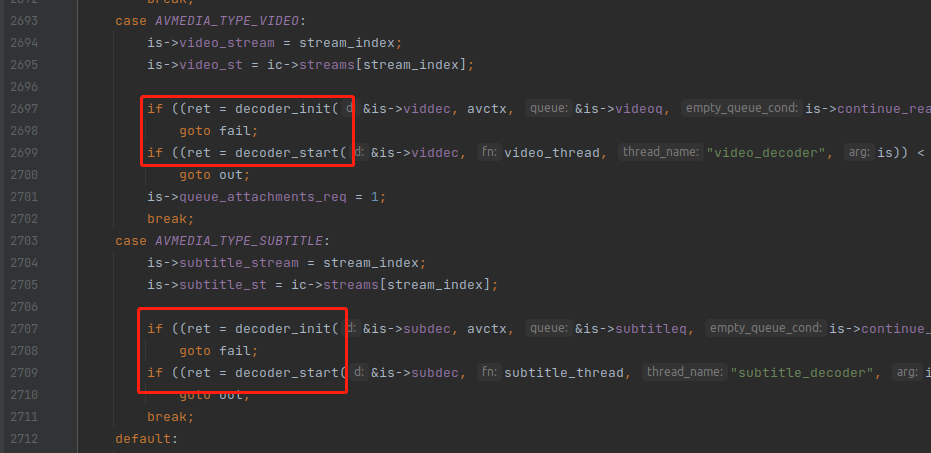
stream_component_open()函数分析完毕,祝各位读者中秋节快乐。
